Efficient Information Retrieval from Web Sources for Business Professionals
The Information Retrieval Problem
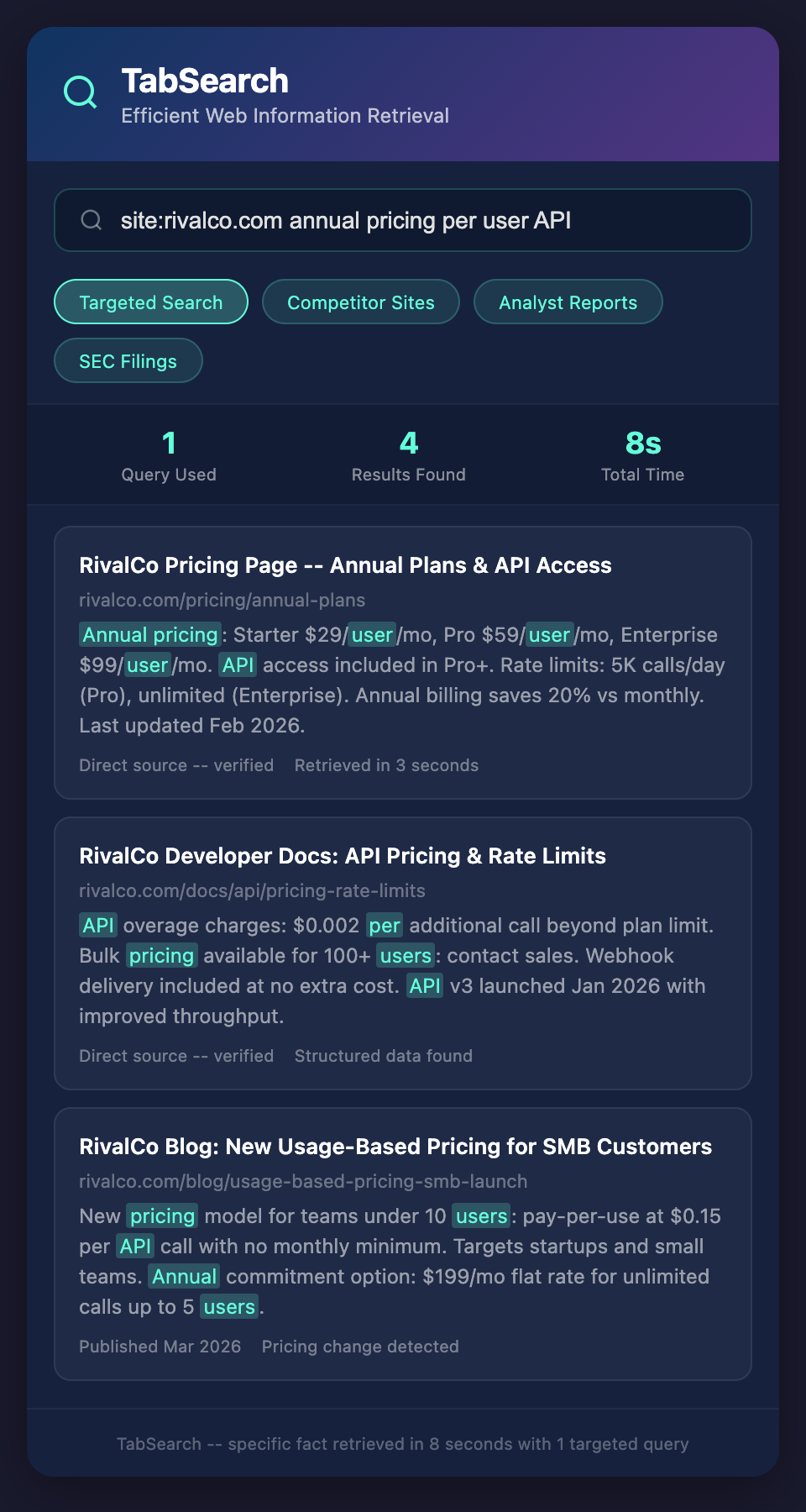
You need a specific fact. A competitor's customer count. An industry growth rate. A vendor's pricing for a specific feature. A regulatory requirement that affects your market.
You know this information exists somewhere on the web. The question is how long will it take you to find it?
With traditional search (Google, Bing), you might try 5-10 queries before finding the answer. Each query takes a minute. Each wrong result you click is a false lead. You spend 15-30 minutes finding one fact.
Multiply this across dozens of facts per project and hundreds of hours yearly are lost to inefficient retrieval.
The problem isn't information scarcity. It's that general-purpose search engines are terrible for finding specific business facts. They're optimized for finding websites people browse casually, not for finding specific data points buried in web content.
Why General Search Fails
Google and Bing are optimized for popularity. The highest-ranking results are pages with most backlinks, most traffic, or most shares. For general queries, this works well.
For specific business data, it fails catastrophically:
Problem 1: Ambiguous queries return hundreds of results
Search "competitor pricing" and you get the competitor's marketing site (not their actual pricing), pricing aggregators that may be outdated, screenshots from years ago, and competitor reviews mentioning pricing.
The actual pricing page is there somewhere, but it's buried on page 5 alongside irrelevant results.
Problem 2: You don't know which sources are authoritative
Is this pricing information from their official website or a third-party aggregator? Is this market data from an analyst firm or a blog? Is this regulatory requirement current or outdated?
General search doesn't tell you source credibility.
Problem 3: Structured data is treated like regular content
If a page contains a pricing table with specific numbers, general search treats it the same as a page that mentions pricing in passing. You get results but can't filter for pages with structured data.
Problem 4: Context-specific data is buried
You need "pricing for API access for companies under 100 users." That specific information exists on a pricing page but is buried in paragraphs. General search returns the main pricing page but doesn't surface the specific data point.
Efficient Information Retrieval Strategies
Professional researchers use strategies to retrieve information faster:
Strategy 1: Search within known sources
Don't search the entire web. Search within sources you trust. If you need industry data, search analyst sites (Gartner, Forrester). If you need regulatory information, search regulatory databases. If you need competitor pricing, search their websites.
Most browsers have a "site:" search operator. "site:competitor.com pricing" finds pricing mentions only on their website. This cuts irrelevant results dramatically.
The efficiency gain: 30-minute search becomes 5-minute search because you're searching a small, relevant corpus instead of the entire web.
Strategy 2: Search for specific data formats
If you need numbers, search for numbers. "Market size $[0-9]+ billion" finds pages mentioning market size in billions. "Growth [0-9]+%" finds pages with growth percentages.
This requires search syntax knowledge but reduces false results significantly.
Strategy 3: Search recent information
General web search doesn't filter by date well. But you can: "market size 2025" or "competitor announcement March 2026." Adding time context reduces outdated results.
Strategy 4: Cross-reference and validate
When you find information, verify it. Does a second source confirm it? Is it consistent with other data you've gathered? Using multiple sources catches errors and gives you confidence in your findings.
The Limitations of Manual Retrieval
Even with strategies, manual web search is inefficient:
-
You have to remember search syntax
-
You have to manually enter searches
-
You have to click through results to verify them
-
You have to cross-reference sources manually
-
You have to decide source credibility manually
-
Finding one fact might require 10 different searches across different sources
For knowledge workers conducting extensive research, this is tedious and slow.
Systematic Information Retrieval
Efficient information retrieval happens when you systematize it:
Build a Research Workflow
Define what data you need. For competitive research:
-
Pricing information (all tiers)
-
Customer count or usage metrics
-
Employee count
-
Recent funding or financial data
-
Product announcements (last 6 months)
-
Customer reviews and ratings
For each data point, define how to find it efficiently:
-
Pricing: Search competitor website for pricing page
-
Customer count: Search press releases and investor reports
-
Employees: LinkedIn company page
-
Recent funding: Tech news sites
-
Product announcements: Company blog
-
Reviews: Review aggregators
This workflow means you're not searching randomly. You're systematically gathering required data.
Create Search Queries in Advance
For each data point, prepare efficient search queries:
-
Pricing: "site:competitor.com pricing plans"
-
Customer count: "competitor customers millions users" on LinkedIn + investor pages
-
Employees: "competitor employees" LinkedIn
-
Recent funding: "competitor funding round 2025 2026"
Pre-written queries execute faster than improvised searches.
Use Specialized Search Tools
General search engines are generalists. Specialized tools are better for specific purposes:
-
Company research: Crunchbase, PitchBook, LinkedIn
-
Financial data: SEC filings, investor relations websites, analyst reports
-
Regulatory information: Government regulatory databases
-
Industry data: Industry analyst reports, trade publications
-
Customer feedback: Review aggregators, social media
-
News: News aggregators with filtering
Each tool is optimized for specific data types. Using the right tool for each data type is more efficient than using general search for everything.
Build a Research Database
As you retrieve information, store it. Instead of retrieving the same fact multiple times, reference your previous research. If you're researching the same competitor quarterly, build a database of retrieved information. Update quarterly instead of starting from scratch.
The Compound Efficiency Gain
Consider a knowledge worker researching 10 competitors quarterly:
Without systematic retrieval:
-
10 competitors × 6 data types × 3 searches each (average 2 wrong turns)
-
180 searches quarterly
-
5 minutes per successful search, 10 minutes per failed search
-
~500 hours annually on competitor research
With systematic retrieval:
-
First quarter: 180 searches, 500 hours
-
Subsequent quarters: 30 update searches (only changed information)
-
Plus 2-3 hours per quarter to review database
-
~100 hours annually after first quarter
The first-year investment pays off year two and beyond.
Information Retrieval as Competitive Advantage
Organizations that retrieve market information efficiently make faster decisions. They know competitive moves faster. They respond to market changes faster.
They also build better knowledge bases. Information captured efficiently accumulates into organizational intelligence.
Master Efficient Retrieval
Information retrieval shouldn't be your bottleneck. It should be systematic and fast.
Join our waitlist to build efficient information retrieval systems that capture data from web sources automatically. Stop searching manually. Start finding answers instantly.