Why Knowledge Workers Lose Critical Market Insights in Browser History
The Broken History Problem
You remember opening a page about competitor pricing two weeks ago. You know it was important. You're 90% certain it was a screenshot of their feature comparison. But scrolling through two weeks of browser history—hundreds of pages in no chronological or categorical order—you can't find it. You give up after 15 minutes and move on, losing valuable competitive data.
This happens constantly. Critical market insights vanish into browser history because:
-
No semantic search: History shows URLs, not content. "cdn.example.com/pricing" doesn't tell you what's on that page.
-
Volume overwhelms recall: After 100 visits, finding one specific page by URL alone is nearly impossible.
-
No context preservation: You remember the insight but not the exact page or date.
-
Time decay: Pages get buried under newer visits. Last week's research becomes unretrievable.
Browser history was designed for "I want to revisit that page I saw earlier." It wasn't designed for "I need every piece of competitive intelligence I've collected across six months."
Why This Costs Organizations Money
Redundant research: Your team researches the same competitor intelligence twice because nobody can find what was already investigated.
Missed pattern recognition: An analyst misses a crucial trend because related research from three weeks ago is forgotten.
Slow decision-making: Finding supporting data takes 20 minutes of digging instead of 20 seconds of searching.
Institutional knowledge loss: When people leave, their research disappears with them. Months of market knowledge is gone.
The Hidden Cost: Time Tax on Knowledge Workers
Calculate the real expense:
If a knowledge worker loses access to 2-3 critical insights per week due to poor research retrieval, that's:
-
15 minutes per incident searching and not finding
-
30 minutes re-researching what was already discovered
-
45 minutes lost per week = 39 hours per year per person
For a team of five knowledge workers, that's 195 hours annually—nearly a full-time person's worth of time—spent re-researching what already exists.
Why Traditional Search Tools Fall Short
Google/Bing history search shows you pages you've visited, but:
-
Only works if you remember the URL structure
-
Doesn't search page content, just titles and URLs
-
Drops older history automatically
-
Doesn't handle pages you've scrolled past without navigating fully
Browser bookmarks help, but require:
-
Manual curation (time cost)
-
Consistent organization (discipline cost)
-
Recall that you bookmarked it (memory cost)
-
You still have to re-read the page when you find it
Pocket/Instapaper and similar collect articles but don't:
-
Capture context (why you saved it, where it fits in your analysis)
-
Index the full content for search
-
Maintain relationships between research sources
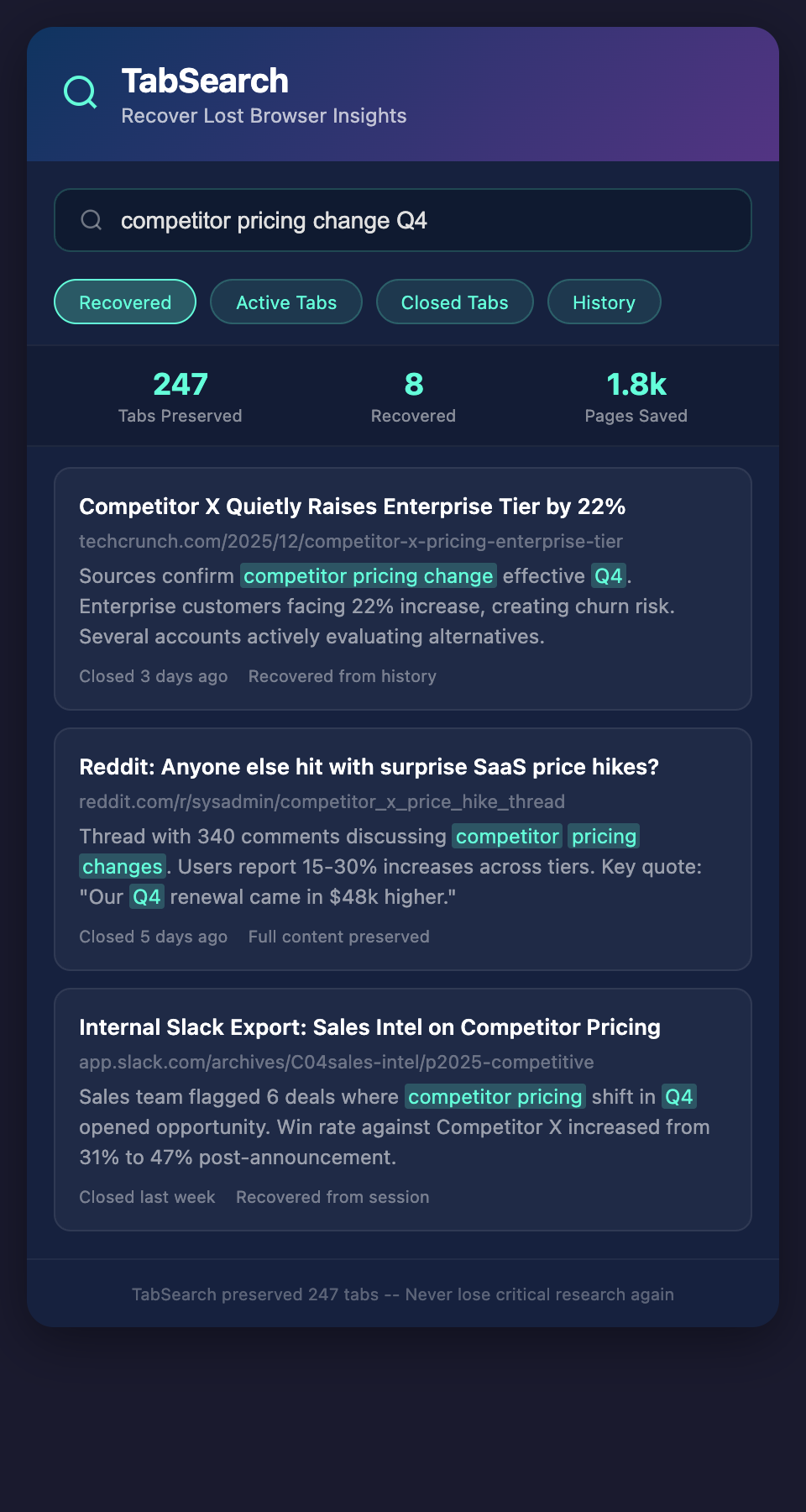
The Solution: Automatic, Full-Text Research Indexing
Imagine every tab you open is automatically indexed and searchable by its actual content. You search "customer retention rates" and get:
-
That pricing page mentioning churn metrics from two weeks ago
-
The earnings call transcript with retention discussion from last month
-
The competitor case study you opened but forgot about
-
The industry report buried under newer tabs
All in one search, with original sources preserved, no manual work required.
How Automatic Indexing Works
When you open a tab, the system:
-
Captures the current content (what's on the page right now)
-
Indexes every word for instant searchability
-
Preserves metadata (URL, timestamp, context)
-
Links related research (if you search competitor X frequently, clusters related findings)
-
Never expires (unlike browser history, this isn't auto-deleted)
You get the benefits of perfect research organization without the work of organizing it.
Real-World Scenario: Board Meeting Preparation
You have 48 hours to prepare a competitive brief for your board. Without automatic indexing:
-
You search browser history: "Slow, manual, incomplete"
-
You ask colleagues via Slack: "They remember fragments, not exact data"
-
You re-visit competitor websites: "Expensive, data might have changed"
-
You dig through notes: "Finding the exact quote takes forever"
With indexed research:
-
You search "competitive threat quarterly growth": instant results
-
You search "market share enterprise": all collected data surfaces
-
You search "pricing by customer size": finds every pricing page you've studied
Board meeting prep drops from 8 hours to 2 hours. You're presenting backed by actual research instead of memory.
Preventing the Data Loss Cycle
Starting today:
-
Recognize the cost: Every forgotten research page costs real time and money
-
Stop relying on memory: Assume you'll forget everything except the system
-
Shift from filing to finding: Don't try to organize perfectly; trust search instead
-
Index proactively: Let the system capture all your research automatically
The Competitive Intelligence Advantage
Organizations that systematically preserve market research outcompete those that lose insights to browser history. Your best competitive intelligence is the research you've already done—if you can find it.
Stop losing critical market insights. Join the waitlist to build a searchable research database that never forgets what you've discovered.