How to Prevent Duplicate Research Across Your Team
The Redundancy Crisis
Your competitive analysis team is three people:
-
Monday: Sarah researches competitor A's market position, writes a 2-page analysis
-
Thursday: Tom starts analyzing competitor A's market position, doesn't see Sarah's work, starts from scratch
-
Same analysis is done twice, one week apart
-
Your team spent 16 hours on the same question
This happens constantly. A 2024 study found that 41% of knowledge workers spend time re-researching information they or colleagues have already analyzed.
The cost: wasted time, fragmented intelligence, inconsistent understanding of market position, and inability to build on previous analysis.
Why Duplicate Research Happens
1. Research is invisible
Teams don't have a shared research repository. Sarah finished her analysis, saved it in a folder on her computer, and moved on. Tom had no way to know it existed.
2. Siloed work
People work on projects in isolation. Competitive analysis on Project A and Project B might overlap, but teams don't coordinate.
3. Institutional memory is weak
"Didn't someone research this?" Team members vaguely remember work being done but can't find it. Rather than spend an hour searching, they start fresh.
4. Async work delays discovery
Sarah sends analysis in Slack. Tom's offline. By the time he reads it, he's already committed to his own analysis.
5. No research catalog
Without a searchable research catalog, finding what exists requires knowing the project, the person, or the date it was done. Random chance plays a role.
The Compounds Problem: Delegation Without Knowledge
Manager to analyst: "Research competitor X's cloud strategy"
Analyst A does the research, creates analysis, presents to manager.
Six months later:
Manager to analyst B: "Research competitor X's cloud strategy"
Analyst B doesn't know the research exists. Does the analysis again. Manager doesn't realize they're seeing the same competitive position, just with six-month-old data.
Without shared research infrastructure, every new person or new project starts from zero.
Systems That Prevent Duplication
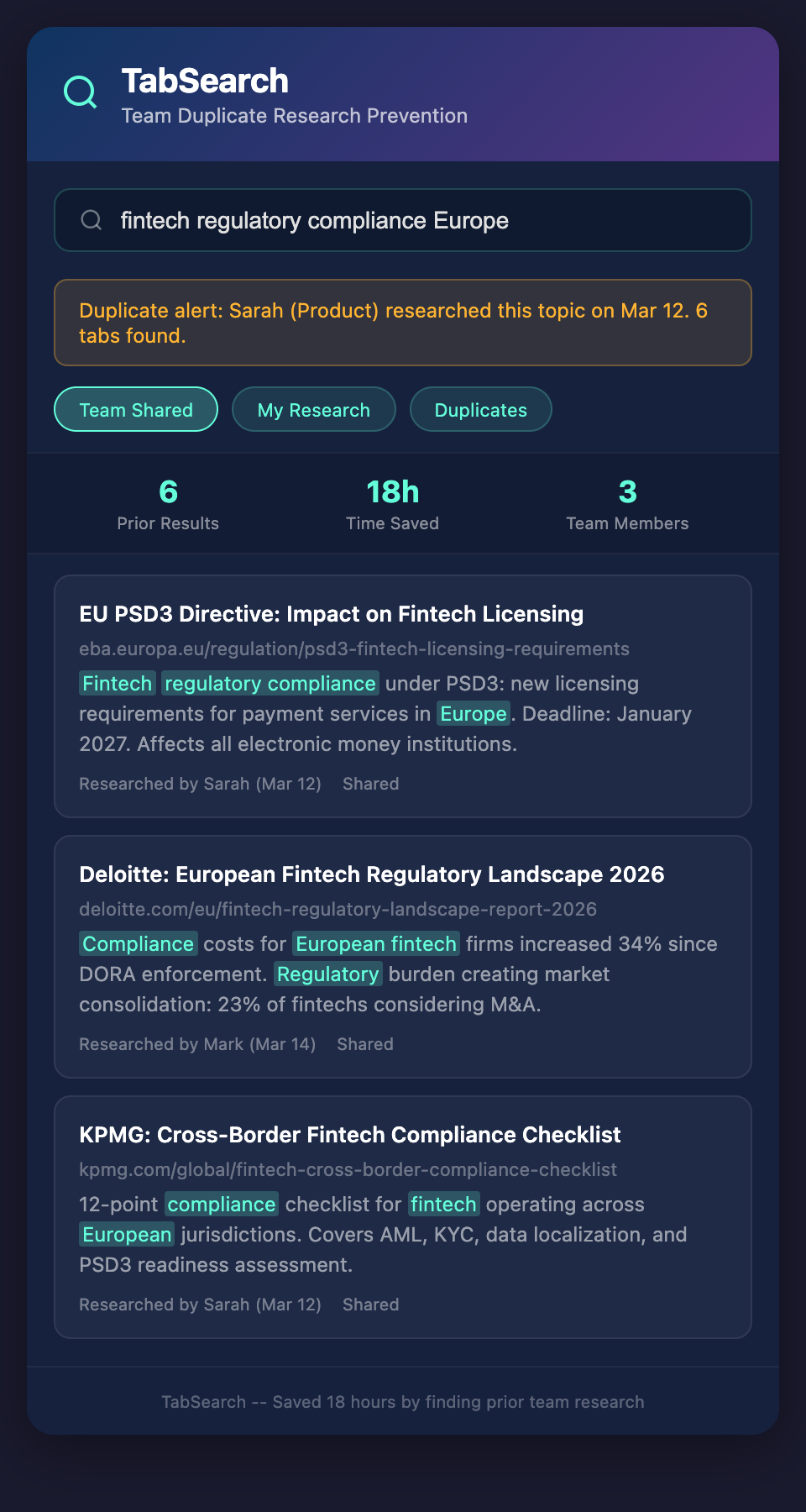
1. Centralized, Searchable Research Repository
All research—articles, analysis, competitive findings—lives in one searchable location:
-
"Has anyone researched competitor X?" Answer comes from searching: 3 articles, 2 analyses
-
"What do we know about their pricing?" Search surfaces pricing research across multiple sources
-
"Has our feature parity changed?" Search timeline shows evolution over months
The repository becomes the institutional memory.
2. Research Requests and Assignments
Formalize research requests:
-
Team member posts research need: "Need current competitive pricing for Q2 planning"
-
Coordinator checks: "We researched this three months ago. Here's what we found."
-
If research is needed, it's assigned to prevent duplication
-
Results feed back into shared repository
Prevents: Three people independently researching the same question
3. Research Index and Metadata
Every research item includes:
-
Topic: What question does this answer?
-
Date: When was this researched/last updated?
-
Source confidence: How reliable is this data?
-
Next review date: When should this be re-researched?
This metadata prevents stale research being used ("our competitive landscape is three years old") and enables easy discovery ("I need Q1 2026 pricing data").
4. Research Freshness Tracking
Competitive intelligence gets stale. A plan:
-
Quarterly topics: Competitor announcements, financial results, customer wins
-
Semi-annual topics: Product roadmap analysis, market positioning shifts
-
Annual topics: Market sizing, long-term strategic direction
Assign owners to "refresh" research at appropriate intervals instead of discovering it's outdated mid-analysis.
5. Cross-Team Communication on Research
Short weekly sync: "What did everyone research this week?"
-
"I analyzed competitor pricing"—capture it, tag it, share it
-
"I found customer churn concerns in reviews"—share with product team
-
"I identified a market expansion opportunity"—brief stakeholders
Communication prevents isolated research.
Real-World Example: Sales Enablement Team
Sales team has 5 people. Each researches competitors independently. Sales manager realizes:
-
Pricing research exists from 3 separate people (3 versions of truth)
-
Feature comparisons exist across 4 different spreadsheets
-
Competitive threat assessments are inconsistent
Implementing shared research repository:
Week 1: Consolidate existing research into searchable database
-
Find 12 different analyses on competitors
-
Identify overlapping research
-
Create metadata (date, confidence, topic)
Week 2: All sales reps trained
-
"Search competitor pricing" → finds all research on topic
-
"Search AI features" → surfaces announcements, positioning, messaging
-
Sales reps spend less time researching, more time selling
Month 1 impact:
-
Zero redundant research (compared to 40% previously)
-
Sales reps save 2 hours/week on research (freed up for selling)
-
Unified intelligence (all reps reference the same competitive data)
Annual impact:
-
80 hours per rep saved on research = 400 hours team productivity
-
Sales rep time better spent on selling = revenue impact
-
Unified messaging improves win rates
Tools That Enable Shared Research
What you need:
-
Central storage (not scattered across email, Slack, shared drives)
-
Full-text search (find research by topic, not by remembering where it's filed)
-
Metadata (know when research was done, how current it is, who contributed)
-
Permission structure (who can add, who can view, who can modify)
-
Version control (know when research was updated and why)
This isn't complex infrastructure. It's a shift from siloed research to shared intelligence.
Building the Habit
Shared research only works if it becomes the default workflow:
Make it easier to search than to research:
-
Searching existing research should take 30 seconds
-
Starting fresh research should take 30 minutes
-
The time incentive should favor sharing
Make contribution lightweight:
-
Analysts don't need to write formal documents
-
Save articles and brief analysis in the system
-
The system handles organization and indexing
Make usage visible:
-
Track how often research is found and used
-
Recognize analyses that multiple people reference
-
Show impact of shared research
Build incrementally:
-
Start with most-researched topics
-
Move to shared repository
-
Expand to other research areas
-
Culture of sharing develops over time
The Competitive Advantage
Organizations that eliminate research duplication have compounding advantages:
-
Faster analysis (no time spent re-researching)
-
Better decisions (building on existing analysis instead of starting fresh)
-
Deeper institutional knowledge (accumulated research compounds over time)
-
Faster onboarding (new analysts inherit research library)
-
Higher quality intelligence (resources focused on synthesis, not collection)
Companies that fragment research across individuals constantly start from zero. Teams that centralize research accelerate exponentially.
Getting Started This Week
-
Audit existing research: Where is competitive intelligence currently living? (Slack, emails, folders, spreadsheets?)
-
Identify top research needs: What topics does your team research repeatedly?
-
Create a shared location for those topics
-
Recruit a research champion to maintain and coordinate
-
Track duplication: How much research overlap exists? Where can you eliminate it?
The ROI of eliminating research duplication is immediate and measurable.
Join the waitlist to build a team research system where insights are shared and duplicate work becomes impossible.