Web Content Indexing Tools for Researchers and Authors
Why Indexing Matters
Searching is only possible if content is properly indexed. Indexing is the process of analyzing content and creating a searchable index that enables fast retrieval.
For writers and researchers, proper indexing of captured web content is the difference between a useful system and a useless one. A system with thousands of captured pages but poor indexing will be slow and return irrelevant results. A system with fewer pages but excellent indexing will be fast and precise.
Understanding indexing helps you choose better tools and understand how to make your research system most effective.
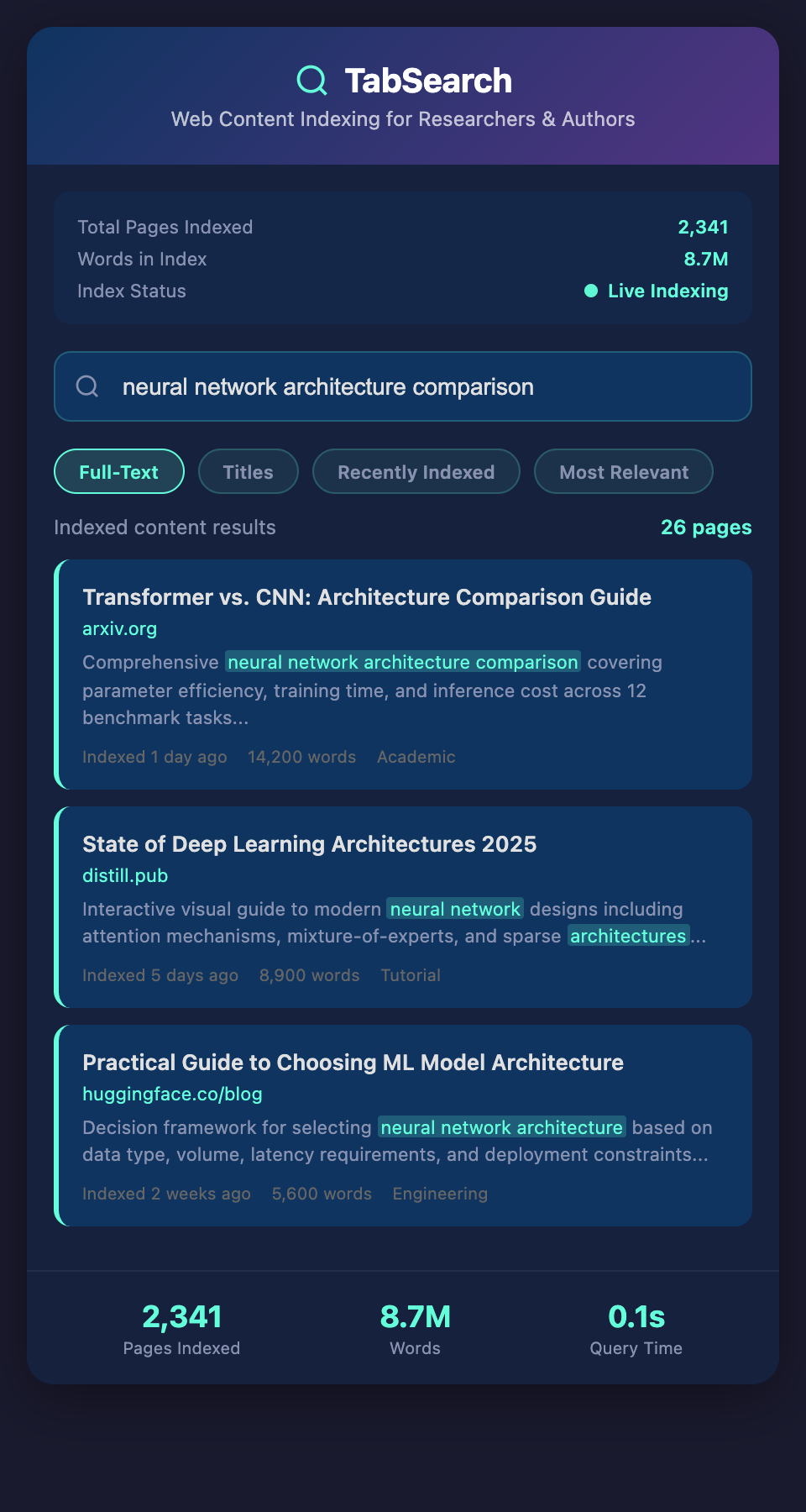
How Full-Text Indexing Works
When you capture a webpage, a full-text indexing system:
-
Extracts the text content from the HTML, removing formatting, ads, navigation, and other non-content elements.
-
Tokenizes the text into individual words or phrases.
-
Removes common words (stop words) that appear everywhere and add noise: "the," "a," "and," etc.
-
Creates an inverted index, a data structure that maps words to the pages containing them.
-
Stores metadata associated with each page: URL, title, author, publication date, your tags.
When you search for "remote work productivity," the system looks up each word in the inverted index, finds pages containing all three words (or however you've structured the query), and returns results ranked by relevance.
This process happens in milliseconds, enabling fast search even across thousands of pages.
Different Indexing Approaches
Not all indexing systems are equal. Different approaches have different tradeoffs:
Full-Text Indexing with Metadata
This is the gold standard for research: every word is indexed, and metadata is preserved and searchable. This approach enables precise queries and fast retrieval.
Advantages: Fast, precise, flexible searching.
Disadvantages: Requires more storage space and processing power.
Headline and Metadata Only
Some systems only index article headlines, publication names, and metadata, not full text.
Advantages: Faster, uses less storage.
Disadvantages: Can't search within article content; limited to searching titles and metadata.
Document-Level Matching
Some systems just track which documents match a search, without showing you where in the document the match occurs.
Advantages: Fast for very large collections.
Disadvantages: Less useful for finding specific information within documents.
For writers and researchers, full-text indexing with metadata is essential. You need to search for specific phrases and find them in context.
Indexing Performance Considerations
As your research library grows, indexing performance becomes important:
Speed. Search should return results in under a second, even with thousands of pages. If search is slow, you'll stop using the system.
Relevance. Results should be ranked by relevance. Most-relevant results should appear first. Simple algorithms rank by frequency (more matches = higher rank). Better algorithms consider contextual factors (e.g., matches in the title are more important than matches in body text).
Scalability. The system should handle growing collections without degrading. A system that works fast with 100 pages might be slow with 10,000. Good indexing systems scale linearly or better.
Building Your Own Index vs. Using Existing Tools
You have two choices: build your own indexing system (technically complex) or use existing tools.
Building your own requires technical skills and ongoing maintenance. You'd need to:
-
Capture pages to a database
-
Implement full-text indexing (or use a library like Elasticsearch)
-
Build a user interface for search
-
Maintain and update the system
This approach gives you total control but requires significant technical effort.
Using existing tools is faster. Many tools handle indexing for you:
-
Browser extensions that capture to a cloud service
-
Desktop applications with local indexing
-
Web applications with remote indexing
The tradeoff is less control, but dramatically less effort.
Choosing an Indexing Tool
If using an existing tool, evaluate on these criteria:
Indexing comprehensiveness. Does it index full text or just metadata?
Search capabilities. Can you use Boolean operators? Phrase search? Filters?
Search speed. How quickly does search return results?
Data ownership. Is your data stored locally (you control it) or in the cloud (provider controls it)?
Privacy. Is indexing done on your device or on remote servers?
Offline access. Can you search offline?
Export/backup. Can you export your indexed data if you want to switch tools?
The Indexing Evolution
As your research library grows, good indexing becomes increasingly valuable. With 100 sources, you can find information through browsing. With 1,000 sources, you absolutely need full-text search. With 10,000+ sources, specialized indexing (filtering by date, source type, topic) becomes essential.
Leverage Indexing for Research Power
Ready to index your web research into a searchable database that returns results instantly, even across thousands of pages? Join our waitlist to get early access to a content indexing system optimized for writers and researchers.