Create an Internal Knowledge Base From Scattered Web Research
Knowledge Evaporates
A senior developer spends two hours researching "how Node.js garbage collection impacts performance." They read three blog posts, a conference talk transcript, and the official documentation. They learn something valuable. They implement an optimization. Then what?
That knowledge evaporates. It's locked in their brain. It's not documented anywhere. The rest of the team doesn't benefit. New team members learn this the hard way instead of learning from existing research.
This happens thousands of times at every organization. Knowledge gets created and lost constantly.
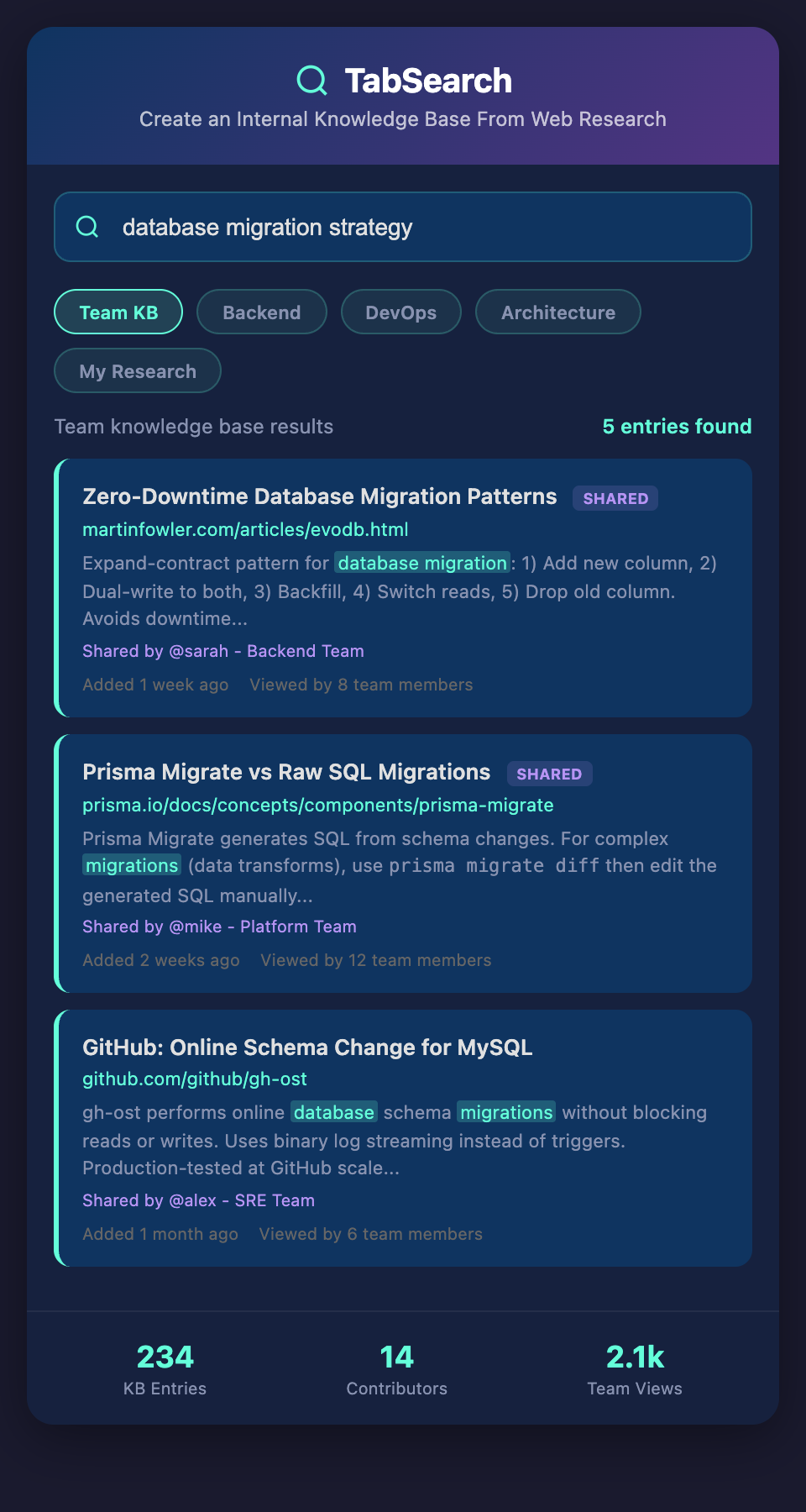
The Problem With Current Documentation
Most teams have insufficient internal documentation because:
Documentation requires separate effort. Someone has to research, then write documentation, then maintain it. That's two jobs. Most people do the first job and skip the second.
No incentive to document. The developer who researches the solution benefits (they learned something), but documenting it requires more time with no direct benefit to them.
Maintenance burden. Documentation gets outdated. The Node.js garbage collection post from 2019 doesn't apply to the 2024 version. Someone has to keep it current.
Not discoverable. Documentation lives in a wiki or a document somewhere. People don't find it because they don't know it exists or they just search Google instead.
What If Research Automatically Became Documentation?
Imagine if every article your team reads, every Stack Overflow answer you evaluate, every documentation page you research automatically became part of your team's knowledge base—without any extra effort.
No one had to write documentation. It was captured passively as your team did their jobs.
When a new team member joins, they can search "caching" and see:
-
The three caching strategies your team has used
-
The blog posts about each approach
-
Implementation examples from your codebase
-
Lessons learned and mistakes to avoid
Learning the team's conventions takes days instead of months.
When you're solving a problem, you search your team's knowledge base and see:
-
Every similar problem your team has solved before
-
The research your team did to evaluate solutions
-
The decision that was made and why
-
The implementation from your codebase
Solving the problem takes hours instead of days.
From Individual Knowledge to Team Knowledge
Here's the workflow:
-
Developer researches a problem. They open tabs, read documentation, find Stack Overflow answers, read blog posts. Normal workflow.
-
Automatic capture. Every page they research is automatically indexed into the team knowledge base.
-
Context preservation. The pages are linked to the project they were working on, the pull request they submitted, the commit message, the code they wrote.
-
Team search. Other developers can search the knowledge base and see what problem was being solved, what solutions were considered, and what was chosen.
No extra documentation work. Knowledge is created as a byproduct of normal development.
Real Example: The Logging Debate
Scenario: Your team needs to decide on a logging library.
Today: Someone researches options. They read about Pino, Winston, Morgan, Bunyan. They evaluate tradeoffs. They choose one. They implement it. They might mention the choice in a PR, but the research evaporates.
Six months later, a new developer joins. They notice you use Pino but don't know why. They wonder if it's the right choice. They might even suggest switching. No one remembers the research that was done.
With a searchable knowledge base: The person researches logging. They read the Pino documentation, a comparison article about Winston vs. Pino, a blog post about structured logging, a company blog about their logging architecture. All of this is automatically indexed with context: "researched for logging library decision in Project X."
Six months later, a new developer joins. They search "logging library" and see all the research. They understand the constraints and the decision. They might have opinions, but they're informed by the research.
Two years later, a developer asks "should we switch logging libraries?" They search the knowledge base, see the original research, check if anything has changed, and make an informed decision.
Building Institutional Memory
Beyond new hire onboarding, this creates institutional memory:
Decisions don't get remade. When you research how to handle errors in async code and decide on a pattern, that decision is documented in the knowledge base. New projects use the same pattern because it's discoverable.
Mistakes don't repeat. When someone encounters a bug with your logging setup and fixes it, that fix and the lessons learned are documented. The next person doesn't make the same mistake.
Best practices emerge. When you have 100+ documented decisions, patterns emerge. You see that you handle authentication differently in different projects. You might standardize.
Innovation is informed. When someone suggests a new approach to something your team does regularly, they can search the knowledge base, understand why the current approach was chosen, and make an informed case for change.
Capturing the Right Context
The key is capturing not just what you researched, but why:
-
What problem were you solving?
-
What were the candidate solutions?
-
What are the tradeoffs?
-
What did you choose and why?
-
How does it work in your codebase?
This context comes from multiple sources: blog posts you read, documentation you researched, code comments you wrote, PR descriptions, commit messages, code itself.
A searchable knowledge base should surface all of it together, so someone looking for "how do we handle errors" sees the complete picture.
The Compound Effect
After one year, your team has researched 50+ problems. The solutions are documented. Onboarding takes half as long.
After two years, you have 100+ decisions documented. You notice patterns and standardize. Your codebase becomes more consistent.
After three years, institutional knowledge is searchable. Anyone can understand why anything was decided. New technical decisions build on historical context instead of being made in isolation.
Preventing Knowledge Silos
This also prevents knowledge silos where only senior developers understand how things work:
You don't have to ask "how do we handle API errors?" You search the knowledge base. You see the research, the decision, the implementation. You understand the why, not just the how.
New developers learn from the entire team's research history, not just from the senior developer who happens to be available for questions.
From Personal to Team Knowledge
The magic is the transition: you don't try to build a knowledge base. You research normally. The knowledge base is automatically created as a byproduct.
Then, your team uses it constantly because it's easier than searching Google or bugging a senior developer.
It becomes the source of truth. Not just historical record, but active tool.
Join the waitlist to build team knowledge. Stop letting valuable research evaporate. We're launching a system that automatically turns every article your team researches into a searchable internal knowledge base—no extra documentation work required.