Integrating Playtest Feedback into RPG Module Development
The Playtest Feedback Problem
Every playtest group has opinions. They thought the combat was too hard. They thought the mystery was too easy. They wanted more roleplay. They wanted less roleplay. They loved the NPC. They hated the NPC.
Raw playtest feedback is contradictory, subjective, and overwhelming. Two groups can play the same adventure and give opposite feedback. Without a systematic approach to processing feedback, you will either change everything (destroying what works) or change nothing (ignoring real problems).
Categorizing Feedback
Sort all feedback into four categories before taking action:
Bugs. Factual errors, broken mechanics, impossible encounters, missing information, logical contradictions. Bugs are objective problems that must be fixed. "The module references a key on page 12, but no room contains the key" is a bug.
Balance issues. Encounters that are too easy or too hard, rewards that are too generous or too stingy, skill check DCs that are consistently missed or trivially succeeded. Balance issues are semi-objective — they are supported by play data rather than just opinion.
Design feedback. Opinions about the adventure's design choices. "The mystery would be better with more suspects" or "the dungeon needs more exploration before the boss fight." Design feedback is subjective but may identify genuine design weaknesses.
Preference feedback. Individual taste. "I do not like political adventures" or "I prefer more combat." Preference feedback tells you about the tester, not about the module. Acknowledge it but do not act on it unless it reveals a market positioning problem.
The Feedback Collection Template
Standardize how you collect feedback from playtest groups:
Post-session questions:
- What was the most memorable moment?
- Where did you feel confused or lost?
- Which encounters felt too easy? Too hard?
- Which NPCs did you find most interesting? Least interesting?
- Did you feel your choices mattered?
- Was there a point where the pace felt too slow or too fast?
- Would you recommend this adventure? Why or why not?
GM-specific questions:
- Were there any points where you could not find the information you needed?
- Which sections were easiest to run? Hardest to run?
- Did any conditional triggers or branching paths create problems?
- How long did each section take compared to your expectations?
- What would you change about the module's organization?
Observation data (collected by the designer during play):
- Time spent on each section
- Which path was chosen at each branch point
- Where players expressed confusion (verbal or behavioral)
- Where engagement was highest and lowest
- Which rules required lookup or adjudication
Processing Feedback
Aggregate across groups. Individual feedback is anecdotal. Feedback patterns across multiple groups are signal. If one group says combat was too hard, it might be their composition. If three groups say it, the combat is too hard.
Weight by frequency. Track how many groups independently identify the same issue. Issues identified by 50% or more of playtest groups are high priority. Issues identified by a single group are low priority unless they are bugs.
Weight by severity. A bug that breaks the adventure is high priority regardless of frequency. A preference that one group dislikes is low priority regardless of how strongly they feel about it.
Separate what from how. Playtesters are reliable reporters of what went wrong but unreliable prescribers of how to fix it. "The combat was too hard" is valuable feedback. "You should remove two of the enemies" is a suggested fix that may or may not be the right approach.
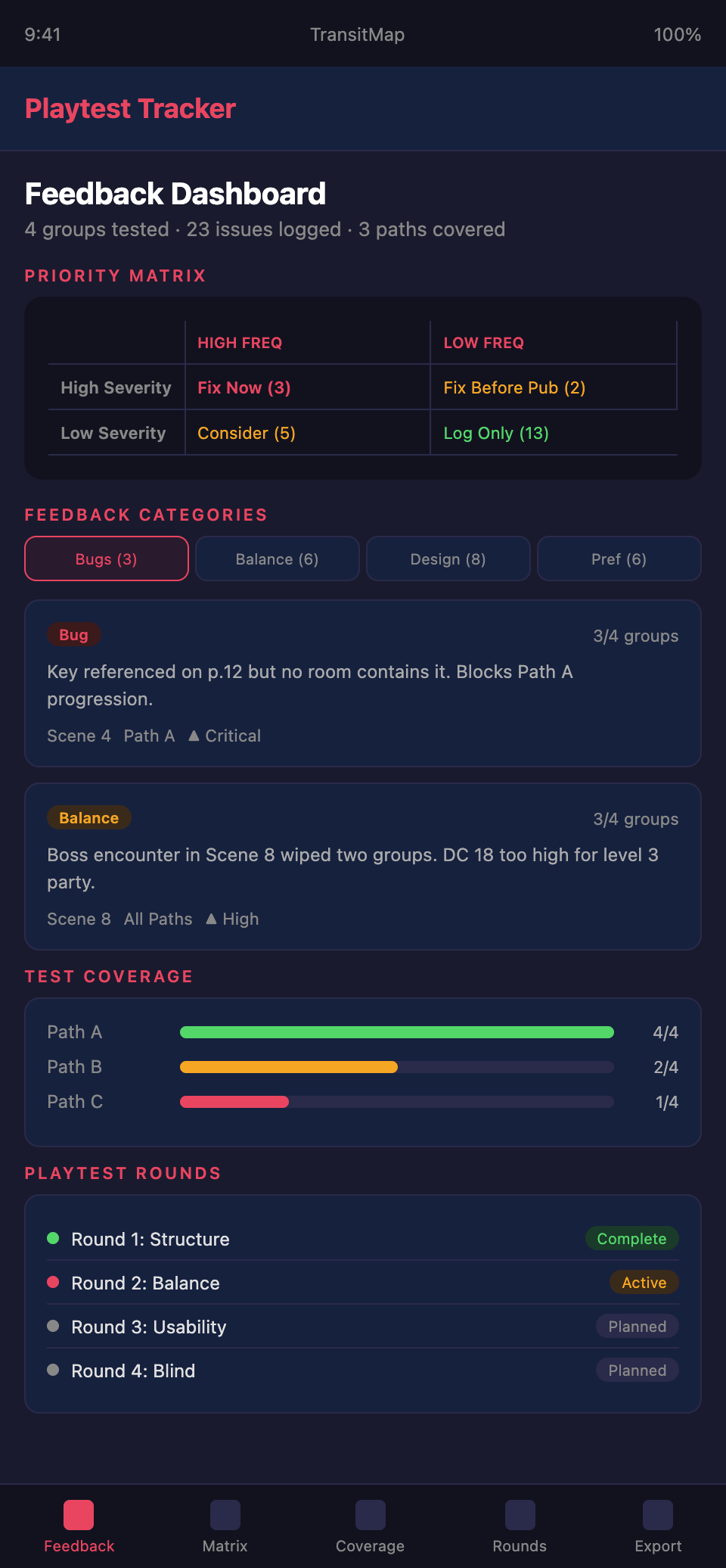
The Revision Priority Matrix
| High Frequency | Low Frequency | |
|---|---|---|
| High Severity | Fix immediately | Fix before publication |
| Low Severity | Consider fixing | Log but do not act |
Quadrant 1 (High Frequency, High Severity): Multiple groups hit the same serious problem. Fix it immediately and retest.
Quadrant 2 (Low Frequency, High Severity): A serious problem that most groups did not encounter — likely an edge case or path-specific issue. Fix it before publication but do not prioritize over Quadrant 1.
Quadrant 3 (High Frequency, Low Severity): A minor issue that many groups noticed. Consider fixing if the fix is low-effort. Accept if fixing would require significant redesign.
Quadrant 4 (Low Frequency, Low Severity): A minor issue noticed by one group. Log it and move on.
Iterative Playtesting
First round: Structure testing. Test the adventure's overall structure, flow, and pacing. Do not worry about balance fine-tuning — focus on whether the adventure works as an experience.
Second round: Balance testing. With structural issues resolved, test encounter balance, DC calibration, and reward scaling. Use groups of different compositions and play styles.
Third round: Usability testing. Give the module to GMs who have not been involved in development. Can they understand it, prep it, and run it without outside guidance? This tests the module as a product, not just as an adventure.
Final round: Blind testing. Give the module to GMs with no interaction from you. They read it, prep it, run it, and report back. This simulates the customer experience.
Integrating playtest feedback into a complex module? Join the TransitMap waitlist — track feedback by scene and path, visualize which branches have been tested, and prioritize revisions with a clear view of your adventure's tested and untested content.