What Continuous Fatigue Streams Mean for Wind O&M
Two Streams, One Missing
An O&M engineer in a Danish ops room watches three screens. One shows live SCADA telemetry from 88 turbines. Another shows continuous vibration traces from the gearbox monitoring fleet. The third shows a stale PDF of last month's crew fatigue survey, manually assembled by the HSE lead from SOV sign-off forms. Two of those screens update by the second. One updates by the fortnight. The engineer has to make a dispatch decision right now, and two-thirds of the data she needs is fresh.
The sector knows this pattern. ONYX Insight's coverage of predictive analytics in offshore wind O&M describes continuous SCADA, vibration, and temperature streams as the anchor of modern predictive maintenance. A peer-reviewed MDPI Energies paper on advanced monitoring cost-benefit for OWFs shows continuous condition monitoring drops O&M cost while vibration and SCADA streams anchor the PdM model. A broader MDPI Energies survey of predictive and prescriptive wind O&M calls continuous data streams the backbone of next-generation wind O&M — for hardware. For crew, the same industry still runs on two-week latency.
The asymmetry has a history. When the sector first wired gearboxes into continuous monitoring a decade ago, the argument was simple: a bearing failure that the fortnightly read would have missed was worth six figures in unscheduled callout and crane mobilisation. The economic case written itself. The crew-state equivalent has been harder to build because the cost of a missed bloom signal shows up as a reportable incident in a quarterly G+ return rather than as a line item in a callout invoice.
The invoice is visible; the incident is statistical. Opcos that have crossed that reasoning gap — Orsted, Equinor, SSE, Vattenfall in various pilot deployments — have each done so because a specific phase lead or HSE director made the institutional argument inside the firm before the commercial case was cleanly provable on the ledger. Continuous crew streaming is at the stage that continuous vibration streaming was in 2014: the technology is ready, the research base is solid, and the decision is organisational.
Planting a Continuous Crew-State Stream
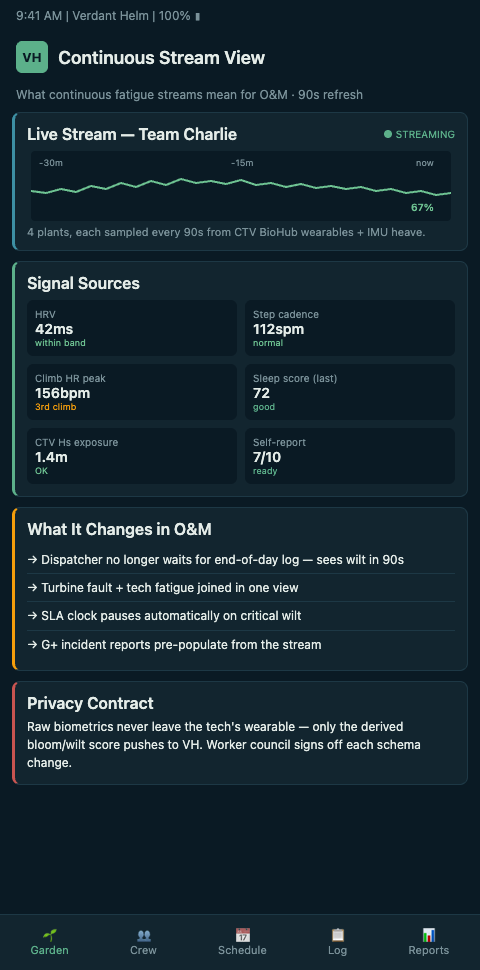
Treat the fatigue data as soil moisture in the garden. It does not help to measure it once a fortnight. The whole premise of a living garden is that moisture readings are current enough to drive the next watering decision. In Verdant Helm, each tech bed carries a continuous bloom state built from four always-on inputs: a self-reported daily sleep and readiness tick (thirty seconds on a tablet at the CTV dock), a wearable HR/HRV aggregate if the tech opts in, logged climb and transfer counts flowing from the dispatch system, and near-miss or fatigue-note submissions from the SOV medic and phase lead. The stream runs as long as the tech is on rotation, and the bloom colour recomputes every time a signal updates.
The ingestion design needs to handle the messy realities of offshore operations. Satellite backhaul drops during transits mean stream writes must buffer locally on the SOV and reconcile on reconnect. Wearable batteries die mid-window and the stream needs to degrade gracefully when the HR/HRV input goes silent for 12 hours. The daily readiness tick must be frictionless enough that techs actually complete it at 06:15 before boarding — anything over 30 seconds kills compliance. Near-miss submissions need an optional quick-log format for the field and a richer form for the SOV back at base, with both feeding the same downstream signal. Every one of these design details determines whether the stream is actually continuous in practice or just continuous on the architecture slide.
The Frontiers in Physiology review of wearable fatigue monitoring maps the measurement stack: HR, HRV, EEG, EMG, motion, all capturable in non-intrusive form. A systematic PMC review of smart wearables for occupational physical fatigue confirms these signals detect physical fatigue across shift-work sectors, including maritime and offshore. The National Safety Council's Work-to-Zero brief on fatigue monitoring and wearables documents measurable reductions in fatigue-related incidents when wearable streams feed into dispatch decisions — not when they sit on a research shelf.
What actually changes when the crew-state signal becomes continuous: the dispatcher stops reading fatigue as a past-tense summary and starts reading it as a current state. A CTV transfer pulled at 07:15 because the tech's overnight HRV shows acute recovery debt is a decision that cannot happen on fortnightly reporting. A gearbox climb reassigned at 13:30 because the originally-rostered tech logged a near-miss twenty minutes earlier is a decision the paper log cannot support. The stream becomes the enabler for the garden's prune action to fire at the right timescale.
The temporal granularity cascades into operational consequence. Decisions that took 48 hours under the fortnightly model now happen in 15 minutes. A dispatcher who used to have to wait for the next fatigue form cycle before reassigning a climb can reassign it in real time. A phase lead who used to wait weeks to see whether a pattern of near-misses correlated with fatigue can now see the correlation within the same window. An HSE lead who used to prepare a quarterly review from stale data can now prepare a monthly review from current data, and the review itself becomes a real decision forum rather than a retrospective. The change in cadence is the change in authority: continuous data shifts the locus of operational judgment toward the people who see the data soonest.
The DOE/NREL O&M roadmap for U.S. offshore wind already flags continuous data streaming as a strategic O&M research priority. The crew-state stream fits the same architectural slot. It reuses the SDN/IIoT-edge pattern that gearbox telemetry already rides, uses the same satellite backhaul, and writes into the same time-series database that holds vibration traces. Verdant Helm's crew-stream tables sit alongside the SCADA tables rather than in a separate HR system, which keeps joint queries — "which wilt events correlated with near-miss clusters in the last window" — a single SQL away.
The operational payback takes roughly one season to materialise. In the first three months, the stream produces data that confirms what the HSE lead already suspected about the roster — not a revelation, but a calibration. In months four through six, the stream starts catching drift the old reporting would have missed: a tech's gradual HRV narrowing across four windows, a pair whose bloom colours covary in a way that suggests pairing-induced stress, a turbine whose climb pattern produces wilt more reliably than its peers. By month nine, the stream is driving dispatch decisions that would not have happened otherwise, and the opco can trace specific LTI avoidances to specific stream-triggered prunes. That is the evidence that justifies the next year's continued investment in the stream layer.
Advanced Tactics
Three tactical choices separate a continuous crew stream that works from one that gets switched off after six months.
First, preserve reporting trust or lose the stream. The tech-reported inputs — sleep, readiness, near-miss notes — only stay useful if the submission does not become a disciplinary record. Verdant Helm stores submissions at the bloom-signal layer, exposes aggregated colour to the dispatcher, and retains raw submission access only to occupational health and the tech themselves. When techs see that a rough night does not trigger a manager conversation, the next rough night gets logged honestly. When they see the opposite, the stream goes dark inside a fortnight and the garden with it.
Second, ingest at stream rate but decide at dispatch rate. The continuous stream generates enormous volumes of data that no human can watch in real time. The dispatcher does not need a per-second view; the dispatcher needs a bloom colour that recomputes before the next dispatch decision. Verdant Helm's architecture runs a hot path (stream-to-colour recomputation on every input) and a warm path (hourly aggregates for forecasting). The hot path drives dispatch; the warm path drives the 14-day bloom forecast. Conflating the two produces a dashboard nobody can act on.
Third, close the loop back to O&M planning. The stream is evidence, not ornament. Bloom-state data should flow into the next quarter's window planning, into the SLA review with the OEM, and into the G+ annual return, or the investment pays back only in individual dispatch decisions. Teams that treat the continuous stream as a real-time dashboard only (rather than a time-series dataset) miss the strategic payback, which is the reason the SCADA and vibration streams eventually justified themselves.
Fourth, build the cross-stream join into the query layer from day one. The stream becomes exponentially more valuable when joined to the SCADA stream, the vibration stream, and the weather-window dataset. A query like "which gearbox climbs during July's stacked window saw wilt-state techs and what was the downstream vibration signal on those gearboxes" needs a schema where all four streams share common keys — timestamp, asset ID, tech ID. Verdant Helm's crew-stream tables are keyed to the same asset hierarchy as the SCADA tables precisely for this reason. Retrofitting the join later is expensive; designing it in is cheap.
Fifth, version the bloom-state schema. The definition of bloom-state colour will evolve as the opco learns what the stream is actually saying about the roster. Every schema change needs an explicit version, a migration path, and a retention policy for historical colour assignments under the old schema. Without versioning, the opco ends up with three years of data that cannot be compared year-over-year, which undermines the strategic payback the loop-closure point depends on.
The continuous stream is part of a connected stack. It feeds the safety layer — G+ safety dashboards fed by energy telemetry turns the stream into sector benchmarking — and the outcome layer — preventing lost time through visible weather-window fatigue maps stream-driven decisions to LTI reductions that show up in year-end reports. For adjacent sectors, continuous telemetry in HSE audits traces the same pattern in a sibling industry where the audit regime is more mature and the integration lessons transfer back to wind.
Stand Up the Stream This Quarter
Offshore Wind Ops teams comfortable with continuous SCADA and vibration can point Verdant Helm at one CTV, one SOV, and ten techs for a 30-day pilot. Deploy the daily readiness tick at the CTV dock, wire the dispatch logs to the stream ingest, and start the bloom recomputation as a read-only layer next to the SCADA view. By day thirty the O&M engineer who has been squinting at a fortnightly PDF will be able to answer "how tired is this roster right now" from the same screen that holds the gearbox trace. That is the moment the stream becomes permanent.
Run the pilot read-only for the full 30 days. The temptation to start making dispatch calls from the bloom colour in week two is strong, especially when the first stream-visible wilt signal lands. Hold the discipline. Read-only means the HSE lead and the dispatcher see the same signal but the authority still lives with the existing reporting cycle. By the end of the 30 days, the HSE lead has a document showing which dispatch decisions the stream would have prompted differently, and the document becomes the input to a structured conversation with the charterer and the operator's safety officer about shifting authority into the stream.
Budget three additional resources the pilot plan usually underestimates. The CTV master needs 20 minutes of training on the dock-side readiness tick protocol so the 30-second window at 06:15 stays sacred. The SOV medic needs a protocol for logging near-miss submissions from the field, because the quick-log format and the richer form have to converge on the same downstream signal. The phase lead needs a weekly review slot on their calendar for the full 30 days — not to adjudicate the stream but to read it alongside the SCADA view and flag questions. Those three roles, properly scoped, are what turn a 30-day technical pilot into the organisational proof the opco needs to fund the permanent layer.