Machine Translation and Cultural Nuance in Automated Story Stitching
Where Machine Translation Breaks on Grief
A grandson submits a memorial story in Vietnamese describing how his grandmother "lived with one foot in the village and one foot in Philadelphia." Pushed through a consumer translation API, the line comes out as "she had one foot in the village and one foot in Philadelphia" — literally accurate, culturally inert. The implied meaning about divided identity and migrant longing vanishes. The family reads the translation and feels the story has been reduced to geography.
This failure is documented in the machine translation literature. A PMC overview of machine translation challenges catalogs how large language models mishandle idioms and culturally grounded expressions. Research published on arXiv in 2023 introducing the CAMT benchmark established the CSI-Match metric specifically because automated quality scores miss cultural nuance. A Cambridge University Press survey of context in neural machine translation confirms that BLEU and ChrF — the industry's default quality metrics — systematically miss culturally grounded translation errors. A 2025 arXiv study on cultural nuance in LLM translations reaches the same conclusion for the latest generation of models.
For memorial content this is acute. Grief narratives are dense with idiom, metaphor, and culturally specific reference. Research on literary text neural machine translation shows exactly where machine systems falter: the same territory where memorial stories live.
Human-in-the-Loop Translation as Tapestry Stitching
The tapestry metaphor clarifies the solution. A tapestry's threads cross; the loom holds tension; a weaver makes judgment calls at every intersection. Machine translation produces the threads. A human weaver decides where they cross. StoryTapestry combines the two by routing every memorial translation through a staged human-in-the-loop process that treats MT output as a first draft, not a final product.
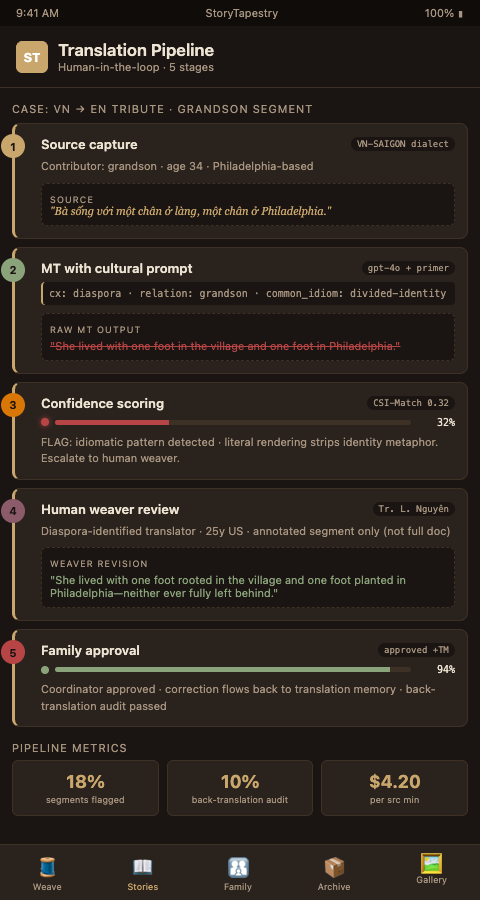
Five stages move a submitted story from source language to published translation:
Stage 1: Source capture with metadata. The contributor submits a story with explicit language, dialect, and cultural-context tags. A contribution from a speaker of Kerala Malayalam is tagged differently than one from a speaker of Gulf-diaspora Malayalam. This tagging drives downstream translation memory lookups and model prompt selection.
Stage 2: Machine translation with cultural prompting. Rather than generic translation, StoryTapestry prompts the model with cultural context. The prompt includes the decedent's cultural background, the contributor's relationship, and any known idiomatic patterns. This reduces — though does not eliminate — the flattening that generic APIs produce. The prompt-engineering approach draws on the same direction as KUDO's live speech translation architecture.
Stage 3: Confidence scoring. The system scores every translated segment for confidence, not quality. Segments with low confidence flag for human review. A segment rendering "one foot in the village" literally would score low-confidence against the cultural-context pattern and escalate automatically.
Stage 4: Human weaver review. A translator reviews flagged segments, leaves annotations in the margin, and commits corrections to the translation memory. This is the tapestry's loom tension point — where a human decides which cultural thread should cross which. The translator does not redo the whole story; they focus on the 15-25% of segments flagged by the confidence model.
Stage 5: Family approval. Before publication, the coordinating family member reviews the final translated version in their preferred display language. Corrections here flow back into the translation memory for the next family's use. This is the collaborative workflow pattern described in Google Workspace's real-time editing documentation, adapted to grief content.
The tapestry is the right metaphor because translation is not a conveyor belt. A conveyor belt assumes uniform input and predictable output. Memorial translation is more like grief language translation across cultures — idiosyncratic input, context-dependent output, and judgment calls on every thread. The parallel with multilingual collaboration tools runs even deeper when translations happen in real time during live memorial gatherings.
The human-in-the-loop architecture also addresses a subtler risk in fully automated translation: the tendency of large language models to smooth out the specific, the regional, and the idiosyncratic in favor of generic, standard, widely attested phrasing. A Ga contributor's tribute with its characteristic rhythmic structures gets flattened into generic English prose; a Galician elder's tribute loses the Galician specificity that distinguishes it from Castilian Spanish; a Louisiana Creole tribute gets rendered as standard French or standard English with no trace of Kreyol texture. Pure machine translation is biased toward the most common patterns in its training data, which means it consistently strips away exactly the markers that make a specific speaker identifiable as themselves. Human weavers, especially those who speak the specific variant natively, are the correction mechanism that keeps translated tributes from sounding like they were written by no one in particular.
Advanced Tactics for Culturally Grounded Translation
Four tactics separate memorial translation programs that serve diaspora families from those that frustrate them:
Build custom glossaries per family. Every memorial case should have a small, persistent glossary — 10 to 30 terms — that captures the decedent's specific vocabulary. If Amal always called her youngest granddaughter "my clementine," that term belongs in the case glossary, and every translator working the case honors it. Without this, one translator renders it literally and another leaves it in the source language, and the published tapestry looks incoherent.
Pay translators per minute of source audio, not per word of output. Word-count pricing penalizes careful translators who preserve short idiomatic phrases. Minute-of-source pricing aligns translator incentives with family needs. Your most careful translator working a five-minute voice note may produce 400 words or 900 — pricing on input removes the perverse incentive to pad.
Use AI for first-pass summaries, humans for final prose. For long contributions, AI produces an accurate summary that the translator uses as scaffolding. Then the translator writes the final prose from the source. This is faster than pure human translation and more accurate than pure MT. The hybrid approach mirrors what AI memorial matching systems do for veterans: AI finds candidates, humans finalize matches.
Run back-translation audits on 10% of published translations. Take the published English version, back-translate it to the source language using a different model, and compare to the original submission. Divergences in meaning (not phrasing) signal translation failures. This 10% audit catches the failures that slip past confidence scoring.
Prefer translators who are themselves part of the diaspora. A Vietnamese translator who has lived in the United States for 25 years understands both sides of Amal's line about feet in different countries. A translator in Hanoi working from text may not. When hiring your translator pool, over-weight diaspora identity.
Escalate culturally ambiguous passages to cultural advisors rather than translators. Some passages are technically translatable but culturally fraught. A Filipino elder's reference to a specific church-adjacent ritual practice may be rendered correctly by any translator but land wrong for non-Filipino readers without cultural context. StoryTapestry's workflow escalates these passages to a cultural advisor for a brief contextual annotation that accompanies the translation, so readers understand not only what the words mean but what the reference carries. Cultural advisors provide value at moments translators alone cannot.
Build feedback loops from family reviewers into translator training. When a family coordinator corrects a translation, capture the specific correction, the original, and the family's reasoning. Aggregate these corrections into quarterly training refreshers for your translator pool. Over 12 to 18 months, this accumulated feedback creates translators who understand the specific preferences of your regional communities in ways generic translator training cannot provide. The funeral home's translator pool becomes a specialized asset rather than an interchangeable utility.
Preserve code-switched passages rather than forcing monolingual resolution. Many diaspora contributors naturally move between two or three languages within a single sentence, and machine translation consistently flattens these passages into the target language alone. StoryTapestry's translator workflow preserves the original code-switched passage alongside the target-language rendering, so readers fluent in both languages see the speaker's actual voice and readers fluent in only one see the meaning. A Dominican-American contributor's phrase blending Spanish and English stays in that blended form in the primary rendering, with translation as accompaniment rather than replacement.
Take the Next Step
StoryTapestry's translation workflow was engineered from the start for memorial content — not adapted from a generic translation platform. If you run diaspora memorial services and are tired of translations that feel flat, we will run one of your recent transnational cases through our workflow as a benchmark. Share a redacted sample contribution and we will return the staged output within five business days. Email our translation-operations lead to schedule. The benchmark includes the source capture with full metadata, the machine translation with cultural prompting, the confidence-scored output flagging segments for human review, the human weaver's revisions, and the final family-reviewed version. We provide side-by-side comparison with whatever your current workflow produces so you can evaluate the difference in quality, cost, and turnaround time directly.
Funeral homes that run this benchmark typically discover that their current translations are dropping nuance their families actually notice, and the hybrid human-in-the-loop workflow catches those drops consistently. The benchmark is free of charge because we believe funeral directors should make translation decisions based on evidence rather than sales pitches, and we have enough confidence in the workflow that we welcome direct comparison. Your families are worth more than flat translations, and the infrastructure to do better exists today. After the benchmark, if you choose to move forward, the onboarding includes translator pool setup, cultural advisor contracting, confidence threshold calibration to your specific case mix, and integration with your existing case management system. Most funeral services complete onboarding within four weeks of the benchmark decision.