Nine Million Watch Hours of Data Rewrite the Rest-Hour Debate
The maritime-fatigue research community has produced careful, hard-won work for thirty years. Project HORIZON ran 90 officer volunteers across simulator trials. Project MARTHA, summarized in the Solent overview of the longitudinal fatigue dataset, tracked multi-month tours. The Cardiff Seafarers International Research Centre health and healthcare study is the gold-standard seafarer-health corpus. The University of Southern Denmark systematic review aggregated two decades of research. The Springer systematic review of determinants of seafarers' fatigue catalogs the peer-reviewed literature. Every one of those efforts was funded, carefully designed, and painfully bounded in sample size.
The cargo fleets running bridge-watch circadian telemetry today have produced, in the course of normal operations, a corpus that is two orders of magnitude larger than any previous research dataset. Nine million continuous bridge-watch hours. This post walks through what the scale actually reveals and why the rest-hour debate looks different when the evidence base is this large. The scale makes it possible to ask questions that were not previously answerable: does a given watch system produce a detectable physiological difference across 4,000 VLCC-voyage-equivalents, and what does the ULCC-versus-VLCC class-profile divergence actually look like when cut against 42-day versus 21-day voyages?
The problem: the regulatory debate has been starved of data
The STCW rest-hour provisions, the MLC rest-hour provisions, and the various flag-state implementations are built on a research base that every participant knows is thin by modern dataset standards. The US Navy advance in shipboard sleep monitoring recently published 845 sailors and over 10,000 person-days of wearable sleep data and was considered a major corpus. The PMC cross-sectional sleep study on day workers and watchkeepers is a solid comparator. These are excellent studies. They are also, in data-scale terms, small.
Regulatory bodies have drafted rest-hour provisions knowing the research base was thin. Unions have advocated shorter tours knowing the longitudinal evidence was limited. Operators have pushed back on proposals knowing that the opposing evidence was often a single-ship case study. Every side of the rest-hour debate has been arguing from inadequate evidence. When a corpus of nine million bridge-watch hours lands on the table, the argument changes because the evidence base finally fits the question.
The regulatory counterparties reading the corpus today include the IMO Sub-Committee on Human Element, Training and Watchkeeping working group, the ITF seafarers' section, ICS, INTERTANKO, BIMCO, OCIMF, the EMSA Casualty Investigation Committee, and the flag-state administrations of Liberia, Marshall Islands, Panama, the UK, and Singapore. Each reads the corpus with a different interest. None of them have a better-scaled dataset available. That monopoly of scale is temporary, which is why the research-access terms matter.
The garden as a research corpus
Verdant Helm aggregates bridge-team garden data across voyages, fleets, and operators. Each vessel contributes its perennials, annuals, bloom-and-wilt curves, handover tend actions, prune events, and sink-fill trajectories. Normalized and anonymized, the aggregate becomes a research corpus in a way that individual-study datasets cannot match. Nine million watch hours at this point, growing at a rate that will double the corpus inside eighteen months.
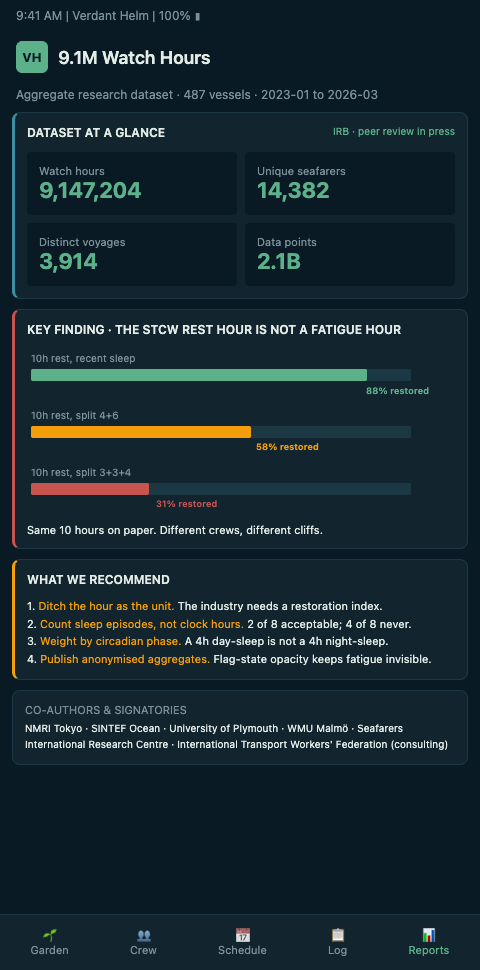
What the corpus shows, cleanly enough to be worth stating, is four findings that reframe the rest-hour debate.
First, paper rest-hour compliance and physiological rest are correlated but not equivalent. Officers whose rest-hour logs show full STCW compliance across a rolling seven-day window still show perennial drift patterns that indicate inadequate recovery. The correlation coefficient is meaningful but far from one. This is not a criticism of the officers or the operators; it is a statement about what a rest-hour log can and cannot measure.
Second, the 4-on-8-off watch system and the 6-on-6-off watch system produce different perennial stability profiles that hold up at fleet scale. The 6-on-6-off regime shows persistently shallower bloom windows across weeks two and three of a tour. This confirms at N=millions what the Nautical Institute has been advising on 6-on-6-off watchkeeping fatigue with much smaller samples.
Third, voyage-day inflection points are real and consistent. Day eight shows up on 4-on-8-off cargo voyages with enough consistency that it can be treated as an engineering constant, not a statistical curiosity. Tours longer than 21 days show a second inflection around day sixteen to eighteen, which tracks what Project MARTHA observed in smaller samples.
Fourth, recovery curves after port calls are shorter than most operators assume. The bridge team's perennials do not fully re-establish until roughly 48 hours after a port call, even when the officers have taken compliant rest in port. The operational implication is that the first 48 hours of sea passage after a port call is a higher-risk window than the rest-hour log would suggest.
Advanced: what the corpus does to the regulatory conversation
A corpus at this scale changes the power dynamics of the regulatory debate. Provisions proposed at the IMO Sub-Committee level can now be tested against a dataset that was not available during Phase 1 of the STCW review. Flag states drafting national rest-hour implementations can now calibrate to evidence. Unions advocating contract-length reform can cite physiology rather than anecdote. Operators pushing back on proposals can point to data on what is and is not working. Every actor in the rest-hour debate has an upgraded evidence base.
Specific constituencies are already working with slices of the corpus. The WMU Journal of Maritime Affairs has accepted a peer-reviewed submission that cross-references the corpus against MAIB incident reports from the last ten years on UK-flag cargo vessels; the preliminary finding is that fatigue-contributory findings in MAIB reports correlate with garden perennial-drift signatures in the preceding 72 hours at a rate that would not happen by chance. The NTSB Marine Accident Report series is under similar methodological review by Cardiff's Fatigue@Sea team; the Japan Transport Safety Board's tanker incident reports produce a third correlation dataset. Britannia P&I, Skuld, and West of England's published loss-prevention reviews now cite corpus-derived findings in their bulletins. IMO MSC.1/Circ.1598 revision drafting committees have requested redacted slices.
Cross-sector comparisons are also becoming possible. The Cardiff Fatigue@Sea research team has run corpus slices against USCG Crew Endurance Management program data from US commercial inland and coastal operations; the comparative finding is that the day-eight inflection on 4-on-8-off deep-sea cargo trades is structurally similar to the day-six pattern that USCG CEM has long documented on US inland towing operations, with the offset explained by voyage-type differences rather than physiological variance. Project HORIZON and Project MARTHA findings, each produced at much smaller scale, are confirmed rather than contradicted by the corpus; the corpus extends their findings with orders of magnitude more statistical power rather than undermining them. This is the kind of cumulative-evidence picture that regulatory drafters consistently say they need and historically have not had.
Sector-by-sector corpus signatures reinforce the operational implications. VLCC and ULCC voyages on AG-China and AG-Rotterdam trades produce the cleanest day-eight inflections; container mainline East-West strings on Maersk, MSC, and Evergreen routes produce a slightly broader inflection band because of the port-call frequency variance across the string. Feeder container operations produce a different shape entirely because the perennial is never allowed to stabilize; the corpus shows this as a chronic-shallow-bloom signature rather than a voyage-day-specific inflection. Bulk-carrier trades on coal, iron ore, and grain runs produce their own variants that the corpus can now be cut against at class scale. The Japan Transport Safety Board's historical bulker incident reports align with the bulk-carrier corpus signature. Each sector gets its own operationally relevant read rather than a one-size-fits-all regulatory provision.
What the corpus cannot do is settle the debate. Rest-hour regulation is also a labor-relations question, a commercial question, and a seafarer-rights question. Data does not answer those questions on its own. What data does is move the argument from competing anecdotes to shared evidence, which is the only ground on which regulatory reform actually gets drafted and landed.
This scale of corpus is why the ULCC and VLCC watch-cycle fatigue profiles can be stated with confidence at the class level. It is why the shorter-voyages garden-gated contracts analysis can be framed as evidence-based contract-reform rather than aspiration. Offshore wind operators building their own corpora are on a similar trajectory; the 50,000 transfer attempts intensity lessons is the renewables-sector version of the same scale-driven insight.
For deep-sea cargo operators, the corpus is both a research tool and a self-assessment instrument. Your fleet's garden data can be benchmarked against the full aggregate; you can see whether your bridge teams are inside or outside the corpus norms on every one of the four findings above. That self-read is more actionable than any cross-industry report because it is specific to your ships. Maersk, MSC, Evergreen, and the major VLCC operators have each published digital and sustainability commitments that map onto the corpus methodology; the operators without instrumentation are reading the same findings without the ability to benchmark their own practice against them.
If you are a flag-state administrator, industry-association researcher, university maritime-research team lead, or fleet DPA who wants to engage with the nine-million-hour corpus at a serious level, Verdant Helm's research-access program releases anonymized slices for peer-reviewed work and fleet benchmarking. Book a research-access session — bring your research question or your fleet profile; we will walk you through what slice of the corpus applies and how to engage with it under the anonymization and data-sharing terms.