Pushing Garden Telemetry to 450 Offshore Turbines
Nine SCADA Rooms, One Tired Fleet
An O&M director walks into the Grimsby ops room on a Tuesday in April holding weather-window briefs for three phases and nine separate SCADA consoles. Phase A's 176 turbines are on a Siemens Omnivise stack. Phase B's 144 are on a Vestas VestasOnline instance. Phase C's 130 are on a hybrid controller nobody wants to touch before the next major overhaul. Crew rosters live in three SharePoint folders, training compliance in WINDA, fatigue in an exit-survey spreadsheet, and incident data in a G+ return that gets assembled quarterly. The question "how tired is my fleet right now" has nine answers, none of them current.
The scale is not hypothetical. Dogger Bank alone is three 1.2 GW phases totalling roughly 277 turbines, and GWEC's 2024 report put global offshore capacity at 83 GW with 8 GW added that year and a forecast of 34 GW per year by 2030. Multi-phase fleets of 400-plus turbines are now the baseline rather than the outlier. The DOE/NREL O&M roadmap for U.S. offshore wind calls fleet-scale monitoring and data standards a core O&M priority, and every opco at that scale is running into the same wall: no unified view of crew state.
The cost of that missing view shows up on specific Tuesday mornings. A storm last Friday compressed four days of planned climbs into a Monday-Tuesday window. Phase A's dispatcher knows her crews absorbed the double. Phase B's dispatcher does not — her Monday roster looked normal and she is stacking Tuesday the same way she would after a quiet week. The SOV crossing between the two phases carries a hidden intensity differential that nobody is reading, and the first near-miss of the week lands in Phase B by 14:00. The director hears about it on Wednesday. The pattern was visible in the data on Friday.
Growing One Garden Across Three Phases
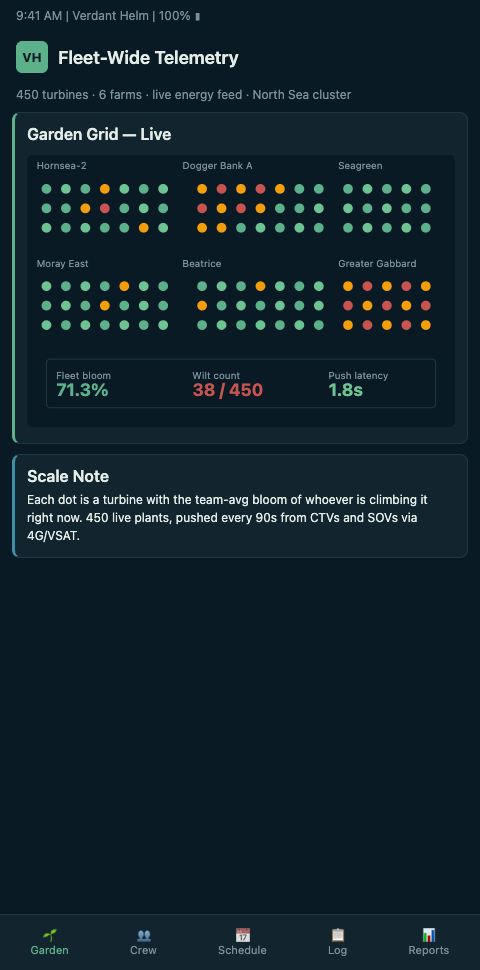
Treat the 450-turbine fleet as a single garden with three beds — one per phase — and each turbine as a flowering stake inside its bed. Each CTV pair becomes a small cluster of perennials that move between stakes during a window. A nacelle becomes a temporary trellis that a tech climbs and descends under measurable intensity load. Verdant Helm renders this as a map layered over the three phase footprints, so the O&M director scanning the Grimsby wall sees nine data sources collapsed into one bloom-wilt-prune gradient across 450 points.
The rollout sequences in four planting cycles. Cycle one plants read-only soil sensors: ingest WINDA, SCADA uptime per asset, CTV transfer logs, and SOV berth occupancy. No dispatch changes yet. Verdant Helm just starts drawing the current bloom state across the three phases. Cycle two lights up phase-local alerting — wilt-risk colours push to each phase lead, and the dispatcher sees forecast-weighted intensity against the bloom map for the next 14 days. Cycle three unifies the fleet view: the director can compare Phase A's recovery ledger against Phase B's hot-window exposure side by side, and the quarterly G+ return writes itself from continuous stream rather than retrospective log scrape.
Each cycle earns the next. Cycle one proves the ingest layer works under real satellite latency and that the three SCADA stacks can co-exist. Cycle two proves the phase leads trust the wilt-risk colours enough to change a dispatch. Cycle three proves the director can make a fleet-level decision — say, shifting a jack-up campaign from Phase C to Phase B because bloom density is higher there — with evidence the finance team will accept. Cycle four proves the loop closes end-to-end, with curtailment logic reading from the same continuous stream that drove the dispatch change. Skipping any cycle produces a rollout that looks complete on the rollout plan and fails on the first real hot window.
The fourth cycle is where most opcos stall and should not. Cycle four writes fatigue triggers back into the SCADA curtailment logic, so a turbine that needs climbing when its assigned tech bed is pruned automatically reprioritises to a nearby bloom-healthy bed or defers until the next window. Fraunhofer IWES Monte Carlo modelling of O&M availability shows telemetry and logistics coupling — not hardware alone — drives availability outcomes in large fleets, which means the fatigue-to-dispatch loop is where yield is actually recovered.
The network layer is the quiet unlock. A 2024 MDPI Energies paper on software-defined IIoT-edge for next-gen offshore wind shows that resilient SDN/IIoT-edge networks, not centralised cloud pushes, are what make latency-sensitive crew telemetry viable at 450-turbine scale. Verdant Helm runs a thin edge agent on each SOV and base that buffers crew-state writes during satellite drop-outs and reconciles on reconnect, so no phase goes dark when the Ka-band blips.
The cycle cadence matters as much as the cycle content. The gap between cycles is where opcos learn what the garden is telling them. Cycle one gets 90 days before cycle two launches; cycle two gets a full CTV season before cycle three unifies the fleet view. The directors who rush this timeline produce data the dispatchers cannot trust, and the rollback from an untrusted system is more expensive than the extra six months of patient planting. One North Sea opco that compressed cycles one through three into a single quarter had to re-run cycle one eighteen months later because the phase leads had stopped logging near-miss context into the pre-tagged feed. Slow planting is fast recovery.
Advanced Tactics
Three moves make the 450-turbine rollout land instead of drift.
First, let SCADA keep its identity. Integrating Verdant Helm as a crew-state sibling to Siemens Omnivise T3000 Wind Offshore Controls or an equivalent REMS, rather than replacing them, is the only politically survivable path across three phases with different OEMs. Map each phase's uptime KPIs to a bloom-weighted availability metric, push those numbers into the existing SCADA Grafana boards, and let the SCADA engineers keep owning their view. The garden becomes an overlay, not a coup.
Second, adopt a portfolio-grade REMS for the integration backplane. Platforms like Power Factors' Renewable Energy Management Suite handle cross-OEM wind, solar, storage across hundreds of sites — which means the integration contract is standardised and the crew-telemetry feed rides the same authentication, the same asset hierarchy, and the same incident taxonomy that finance and regulatory reporting already use. Verdant Helm writes its bloom-state feed as a REMS-native asset stream, not a bespoke dashboard, which keeps the rollout from fragmenting the next time the opco acquires or divests a phase.
Third, tier the phase rollout by weather-window severity rather than calendar. Plant the first phase during a structural low-access window so the initial dispatch changes happen under low pressure. Let cycle-one telemetry run one full CTV season in phase A before touching phase B. The temptation to push all three phases live in Q1 so the year-end board pack looks clean is how rollouts produce data no one trusts. Rushed planting wilts under the first real hot window.
Fourth, invest in the phase-lead training before cycle two. The fleet view is only as honest as the data the phase leads feed into it, and phase leads who have not been through the garden-state schema training will default to the reporting habits they already have. Verdant Helm's rollout ships a three-day phase-lead workshop as part of cycle one — bloom-state taxonomy, near-miss context tagging, ledger mechanics, and the specific dispatch decisions that the fleet view will start driving. The opcos that skip the workshop produce fleet dashboards full of "bloom" colouring that correlates poorly with actual crew state, and the credibility damage to the rollout is hard to reverse.
Fifth, align the rollout milestones with the OpCo's commercial calendar, not the IT calendar. Cycle three unification timed to hit three weeks before the annual O&M contract review is worth more than cycle three timed to hit the end of the fiscal quarter. The fleet view's first strategic consumer is the commercial team negotiating the next SLA, and their window of influence shapes when the unified dashboard lands. Fleet rollouts that treat themselves as infrastructure projects rather than commercial enablers forfeit their first payback.
The 450-turbine garden does not exist in isolation. A burnout-free CTV season is the reference proof the director will want to cite to the ops committee when requesting cycle four. Ranking the greenest offshore wind gardens by operator shows where a fleet-scale rollout lands on the industry scorecard and why the fleet view beats any single-phase case study. And for teams with offshore oil heritage, deploying gardens across 14 North Sea drilling rigs maps the multi-asset rollout pattern onto a sibling sector, with lessons that transfer cleanly back to a 450-turbine wind portfolio.
Spin Up Phase A This Month
Offshore Wind Ops directors steering a multi-phase fleet start Verdant Helm's planting with one phase, one SOV, and one CTV pair. Pick the phase with the cleanest SCADA and the shortest Ka-band hop. Run read-only telemetry for 30 days, present the fleet-view mockup to the ops committee in week four, and set the phase B go-live for the next structural low-access window. That sequence turns a 450-turbine ambition into a rolled-out, operator-owned garden by the end of the season.
Name the cycle-one owner before the first telemetry flow opens. A 450-turbine rollout without a single accountable phase lead turns into a distributed dashboard with nine part-time owners, each waiting for the others to validate the data. The owner should be the Phase A O&M manager with at least five years on the asset — someone whose judgement the director already trusts and whose signature on the cycle-one sign-off will carry weight into cycle two. The owner also carries the authority to shut down a misreading telemetry feed before it drifts into the Phase B dispatchers' daily rhythm, which is the single most common failure pattern in fleet rollouts.
Budget for cycle four explicitly in the initial rollout plan even if it launches eighteen months out. The curtailment writeback loop is where fleet-scale yield actually gets recovered, and opcos who treat cycle four as an optional extension after cycle three typically never schedule it. Wire cycle four into the board-approved rollout plan from cycle one — not as a commitment to build it on schedule, but as a commitment to design cycles one through three in a way that does not foreclose cycle four's architecture. Phase leads will plant cleaner telemetry when they know the data will eventually close back into the dispatch loop, and the commercial team will negotiate the next SLA with cycle four on the roadmap rather than outside it.