How to Audit Sensor Survival After a Direct Hurricane Hit
The Gaslit Dashboard Problem
A Charlotte County grove told us their post-Ian recovery walk turned up 14 sensors physically destroyed — and 31 more that were broadcasting "zero" salt conductivity and "zero" wind gust values because the probe itself had been severed from the logger board. On the dashboard, the 31 silent sensors looked like healthy blocks reporting no salt event. The actual blocks were gone. The sensor network was technically "up" per the gateway status, but the downstream data was worse than useless — it was confidently wrong.
The consequence showed up in the post-storm recovery decisions. Blocks with silent-zero sensors got classified as "unaffected" in the dashboard's initial damage map, which deprioritized them in the rinse-crew queue and the irrigation-leaching schedule. Meanwhile those blocks had received actual salt deposition in the 800 to 1,200 ppm-hour range during the storm. By the time the physical audit caught up four days later and corrected the map, the 36-hour foliar rinse window had closed on every one of those blocks. The blocks that the dashboard said were safe were the blocks that actually needed priority attention, and the sensor network's silent failure drove the recovery crew to the wrong blocks first.
Research on rechargeable agricultural wireless sensor network (Scientific Reports) documented the failure mode: outdoor WSN nodes are susceptible to heavy rain and wind fragmenting the network links and producing functional failure that is not always caught by basic liveness checks. Real-Time Monitoring of Hurricane Winds using Wireless and Sensor Technology (ResearchGate) described distributed WSN architectures designed for hurricane wind telemetry and the post-event data-integrity checks required to trust the surviving nodes.
The hardware baseline matters. Understanding IP Ratings for IoT Devices (Monarch Innovation) classifies IP66/67/68 enclosures as appropriate for hurricane-survivable agricultural deployments. IP66 Dustproof and Waterproof Testing of SenseCAP (Seeed Studio) provides vendor test data for IP66 LoRaWAN nodes withstanding rain, UV, and salt under field conditions. Even rated enclosures fail under direct impact from wind-driven debris, so the audit is not optional even for hardened networks.
The benchmark: National Data Buoy Center (NOAA NDBC) reports approximately 5 percent data loss under 6-meter wave conditions on purpose-built oceanographic platforms. Grove sensor networks typically run at 10 to 25 percent node loss under direct Cat 2 conditions if the hardware is IP66 rated and properly sited; losses rise to 40 to 60 percent with sub-IP66 hardware or poor siting.
Helm-Charted Post-Storm Audit: Four Phases to Trusted Telemetry
HarvestHelm treats post-storm sensor audit the way a yacht captain treats post-voyage hull inspection: a structured checklist across visible, mechanical, electrical, and data-integrity dimensions, with nothing returned to service until the corresponding check passes. The helm-charted yield forecast flags the post-storm audit as a required prerequisite before trusting any sensor data for harvest or hedging decisions.
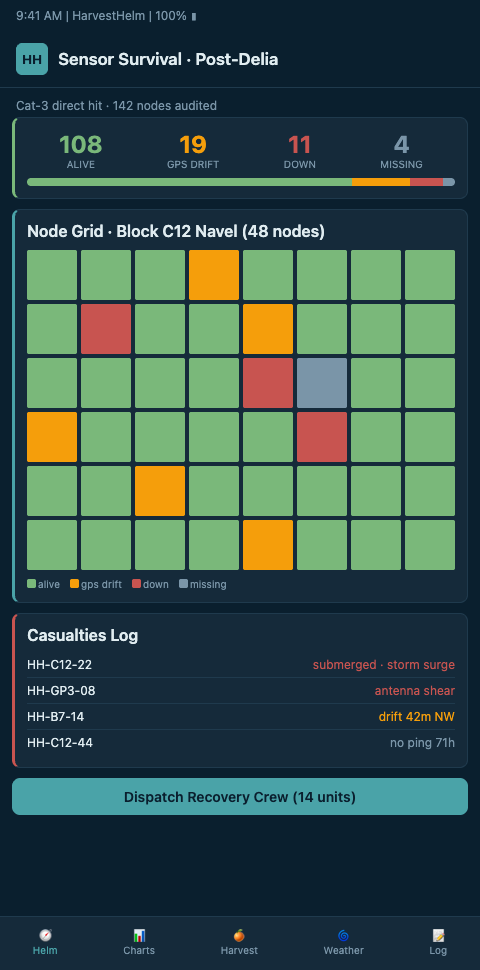
Phase 1: Physical inspection. Walk every sensor location with the block map. Document enclosure integrity, probe mounting, antenna condition, and power supply (battery, solar panel, or mains connection). Photograph each node with GPS tag. Urban Resilience through IoT-Based Disaster Preparedness (ScienceDirect) reviewed IoT sensor survival, redeployment, and infrastructure monitoring protocols post-disaster; the physical inspection phase is where the audit catches the most failures.
Phase 2: Electrical verification. Power-cycle each surviving node. Verify battery voltage under load. Check probe continuity — a severed salt-conductivity probe will often still report power-up telemetry but fail to read meaningful values. Task Force for Reviewing Precision Agriculture Connectivity (FCC) documented that 17 percent of rural America lacks broadband — grove audits must also verify LTE and LoRa gateway survival, not just node-level hardware.
Phase 3: Data integrity. Compare post-storm sensor readings against pre-storm baselines, neighboring-node cross-validation, and known-good reference stations (NWS, NOAA, nearby private weather stations). Flag nodes reporting statistically implausible values — zero salt conductivity in a block that experienced direct sea-spray exposure, for example, is a near-certain sensor failure rather than a real zero reading. HarvestHelm runs the cross-validation automatically and flags suspect nodes for physical re-inspection.
Phase 4: Network integrity. Verify LoRaWAN or cellular backhaul end-to-end. Basics of LoRa Technology for Crop and Livestock Management (NDSU Agriculture) notes LoRaWAN gateway range at 10 to 15 km in open terrain — but storm-damaged line-of-sight, downed trees, and damaged gateway antennas can shrink effective range significantly. The coverage audit compares pre-storm and post-storm gateway reception patterns to identify dead zones.
Our NHC advisory sensors integration relies on the audit being complete before advisory-driven decisions resume using the sensor feed — if the network is reporting gaslit telemetry, the advisory integration will make wrong calls confidently.
Advanced Tactics: Redeployment Priorities, Spare Inventory, and Audit Automation
Not every failed node gets redeployed immediately. HarvestHelm ranks redeployment priority by block economic exposure — windward Valencia blocks on Swingle rootstock get replacement sensors first; interior Hamlin blocks on Cleopatra can wait until the next maintenance window. The yacht-style helm displays the redeployment queue sorted by economic priority, not alphabetical block ID.
Spare inventory is the operational constraint. Groves running 80 to 120 sensor nodes should maintain 15 to 20 percent spare inventory against direct-hit loss rates. Growers who run zero spares spend the post-storm window waiting for vendor shipments while their telemetry stays partial for 3 to 6 weeks. HarvestHelm tracks spare inventory against the loss-rate model and flags procurement recommendations ahead of hurricane season, not after.
Audit automation is the frontier. Full manual audits of 120-node networks take 8 to 16 person-hours depending on grove geography. HarvestHelm's automated data-integrity layer catches 60 to 75 percent of failures without a physical walk, compressing the physical audit to the subset of nodes that actually failed. The physical walk still matters — some failures (mounting damage, antenna detachment) are undetectable from the data alone — but the subset is smaller.
Cross-niche comparison: mountain apple growers running sensor networks for frost monitoring face a related audit problem after late-freeze coverage audit events, where high wind combined with ice loading can damage tower-mounted sensors without obvious ground-level signs. The audit workflow is structurally similar — physical, electrical, data-integrity, network — adapted to the specific hazard profile.
Scaling consideration: our multi-county sensing workflow shows how the audit process scales across geographically distributed grove portfolios. Centralized audit dashboards plus local physical-walk teams produce faster recovery than either alone.
Document the audit. Every post-storm audit cycle should generate a written report — nodes surviving, nodes failed, replacement parts ordered, data-integrity flags raised and resolved. The documentation feeds directly into the USDA disaster claim workflow and informs next-season hardening decisions.
Calibration After Replacement
Replaced sensors do not plug in at factory calibration and start producing useful data. Each replacement requires on-grove calibration against the local baseline so the new node's readings align with the surviving network. A salt-conductivity probe with factory calibration may read 15 to 25 percent high or low relative to the grove's historical baseline, which introduces bias into the block-level threshold math if not corrected.
HarvestHelm's post-replacement calibration workflow runs a 72-hour parallel-reading period where the new sensor's values are compared against a trusted neighboring node under known conditions. The ratio converges to a calibration offset that the dashboard applies to future readings from the new sensor. Growers skipping this step get biased data that silently mis-triggers alerts for the rest of the season.
Multi-node calibration drift is a related concern. After replacing 15 to 20 nodes in a 120-node network, the cumulative calibration picture can shift enough that the whole-grove threshold model needs retuning. HarvestHelm's seasonal recalibration schedule accounts for replacement-driven drift, with full-grove recalibration runs timed to the off-season after significant node replacement events.
Network Topology Decisions Post-Storm
Direct-hit events often reveal topology weaknesses that were not obvious during normal operations. A gateway positioned on a windward ridge for optimal coverage may have survived three seasons before a Cat 2 direct hit destroyed it and knocked out 40 nodes for 72 hours until backup communication was restored. Post-storm is the time to reconsider gateway placement, redundancy, and coverage overlap.
HarvestHelm's post-storm recommendations include topology adjustments when the audit data suggests systematic failure patterns. Two gateway nodes covering overlapping geography provide failover at the cost of hardware; one gateway covering the same area maximizes coverage at the cost of single-point failure. The tradeoff calculation depends on storm frequency, gateway survival rates, and the economic value of continuous telemetry during recovery windows.
Mesh-versus-star topology decisions also warrant review. Star topologies concentrate risk at the gateway; mesh topologies spread risk across nodes but introduce routing complexity. Groves with direct-hit history typically migrate toward partial-mesh architectures with redundant gateways, accepting higher hardware cost in exchange for higher survival rates.
Audit Before You Trust. Zeros Are Not Data.
Coastal Valencia, Hamlin, Murcott, and Navel growers running IoT sensor networks across direct-hit hurricane zones cannot trust the raw telemetry until the four-phase audit confirms hardware, data, and network integrity. HarvestHelm runs physical inspection, electrical verification, data-integrity cross-validation, and network-coverage checks on every node after a direct Cat 2 or higher hit, with economic-priority redeployment queueing built into the helm-charted yield forecast. Zero platform fee. The kilo-cut on successful harvest keeps the tool honest about which sensor data actually earns the right to drive harvest decisions post-storm. Operations joining the pre-season cohort get 15-20% spare inventory sized against their network node count and direct-hit loss rate before June, with IP66-rated replacement hardware staged at the grove rather than waiting on vendor shipment during the 3-to-6-week post-storm scramble.