How Browser Chaos Derails Unknown Parentage Investigations
A Case Unraveled by a Browser Crash
An experienced genetic genealogist was six months into an unknown parentage case. She had built a candidate tree spanning four generations, cross-referencing AncestryDNA matches with census records from FamilySearch, obituaries from Newspapers.com, and one-to-many results from GEDmatch. The working evidence lived across 73 open browser tabs and a handful of notes in a Google Doc. On a Thursday evening, Chrome ran out of memory and crashed. The session restore recovered 58 of the 73 tabs, but the 15 it lost included three GEDmatch one-to-one comparisons and a county court record from a portal that did not support direct linking. Regenerating those comparisons took two weeks — and one of the GEDmatch kits had been deleted in the interim.
This is not an unusual story. Carnegie Mellon researchers found that approximately 25% of study participants experienced browser or computer crashes because they had too many tabs open, and 30% self-identified as having a tab hoarding problem (Carnegie Mellon University, 2021). For genetic genealogists, the stakes of a crash are not just lost productivity. They are lost genealogy evidence — data that may never be recoverable because the source platform has changed.
Unknown parentage investigations are uniquely vulnerable to browser tab overload because of their duration, complexity, and dependence on volatile data sources. A surname research project that takes a weekend is one thing. A parentage case that stretches across months, involving dozens of DNA matches and hundreds of documentary records, creates an accumulation of open tabs that no browser was designed to handle.
Why Unknown Parentage Cases Are Uniquely Fragile
Three characteristics of unknown parentage investigation workflow make them especially susceptible to DNA research tab chaos.
Long duration. The average forensic genetic genealogy case takes over a year to resolve (Stanford Graduate School of Business, 2022). Volunteer-led adoption searches often run even longer. During that timeline, the browser environment changes constantly — updates, crashes, new devices, cleared caches — and so do the platforms. A match that existed in January may be deleted by April. An algorithm update in March may reshuffle your match list by June.
Cross-platform dependency. A typical parentage case requires simultaneous work across AncestryDNA (for match lists and trees), GEDmatch (for segment-level analysis and cross-company matching), FamilySearch (for census and vital records), Newspapers.com (for obituaries), and often multiple state court or vital records portals. Each platform has its own session management, its own timeout behavior, and its own data volatility. Browser tab overload in genealogy is not just about the number of tabs — it is about the number of independent platforms, each capable of expiring your session without warning.
Cascading evidence chains. In parentage work, each piece of evidence depends on others. A DNA match leads to a tree, the tree leads to a census record, the census record leads to a vital record, the vital record confirms or refutes the hypothesis. If any link in that chain is lost — because the tab crashed, the session expired, or the platform changed — reconstructing it requires retracing every preceding step. Parentage case research disorganization does not just lose one document; it can collapse an entire analytical chain.
Turning Chaos Into a Searchable Archive
The solution to DNA research tab chaos is not better tab management. It is making tabs unnecessary as a storage mechanism. When every page you visit during a research session is automatically indexed in a local, searchable archive, losing a tab does not mean losing the content. This is the principle of turning chaotic browser sessions into a searchable private database — the browser becomes a viewing tool, not a filing system.
TabVault implements this for the unknown parentage investigation workflow. As you browse AncestryDNA match pages, GEDmatch comparisons, FamilySearch records, and court portals, each page is captured and indexed locally. When Chrome crashes and takes 15 tabs with it, the content of those pages is already in your archive. When a GEDmatch kit is deleted, the one-to-one comparison you ran against it is preserved in your index.
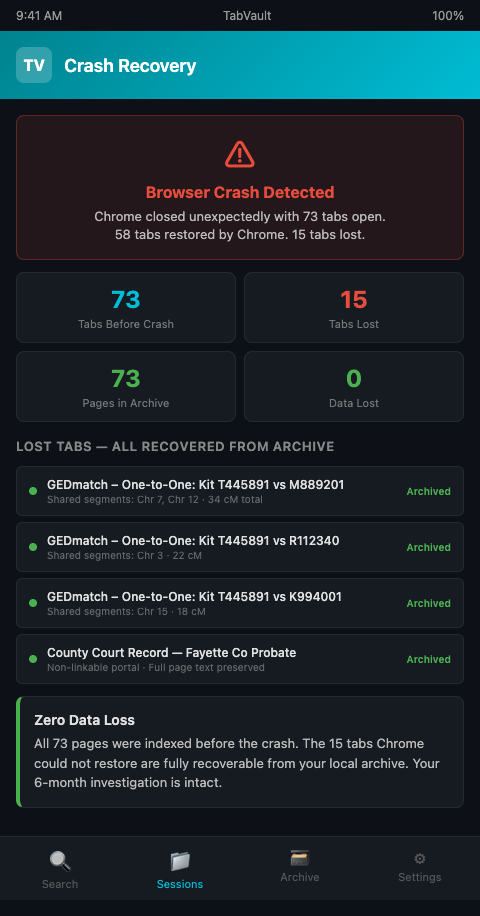
This matters at every stage of the investigation, from the initial broad survey of DNA matches to the final confirmation of a candidate. A researcher who spent three sessions reviewing 80 match pages on Ancestry now has all 80 pages in the archive, searchable by any term that appeared on any page. When new evidence points to a specific geographic area, a search for that location across the archive may surface a match page that was reviewed weeks ago but not flagged at the time — a connection that would be invisible without the archived session.
The cascading evidence chain becomes more resilient too. Because every page in the chain is indexed, you can search backward from any point. If you remember a surname but not which census record contained it, search the archive. If you need the exact centimorgan value from a GEDmatch comparison you ran three months ago, search the archive. The chain does not break because no single tab is the sole repository of any piece of evidence.
This approach directly addresses the problems genealogists face when matches disappear between sessions. The archive preserves what the platforms do not: a historical record of what your research looked like at each point in time.
For a parentage case that may eventually require a formal proof argument under BCG standards, having a complete, timestamped archive of every page consulted during the investigation provides the documentation foundation that manual notes rarely achieve. The archive does not replace analytical work, but it ensures that the raw material for that analysis is always available.
Investigative podcast producers encounter the same structural problem when their source materials vanish mid-investigation. Their uncatalogued research tabs weaken investigative continuity — a vulnerability that indexed sessions eliminate.
Restoring Order to Long-Running Cases
For researchers already deep into a parentage case, here are strategies for bringing existing research under control.
Conduct a tab audit. Open every tab in your current session and let each one index before doing anything else. This is triage: you are getting the existing evidence into the archive before the next crash takes it. Prioritize the most volatile sources — GEDmatch comparisons and state court portals — over more stable ones like FamilySearch.
Reconstruct your analytical chain. After the initial audit, search your archive for the key surnames, locations, and kit numbers in your case. Map the results to your working hypothesis. Identify gaps where you remember viewing a document that did not make it into the index. Where possible, revisit those sources and re-index them.
Index volatile sources immediately. GEDmatch comparisons, county court records, and state vital records portals are the most likely to become inaccessible between sessions. Prioritize indexing these pages before moving to more stable sources like FamilySearch or Ancestry tree pages. A GEDmatch one-to-one comparison that disappears because the other kit was deleted is a permanent loss. A FamilySearch census page that goes temporarily offline will return. Triage accordingly.
Build a case timeline from session dates. Your indexed archive preserves the date of each page capture. Over the course of a months-long investigation, these timestamps create a chronological map of your research — when you first identified a match, when you found the supporting census record, when you located the vital record that confirmed the connection. This timeline is not just useful for your own reference. If your research supports a proof argument under BCG standards, the session dates demonstrate the thoroughness and progression of your investigation.
Adopt a session-first mindset. Going forward, start every research session with a deliberate intention: "Today I am working the maternal line of Case #14." Tag or name the session accordingly. This turns your archive into a structured case file rather than a chronological dump of everything you browsed. A 2024 scoping review in ScienceDirect found that structured information management significantly reduced the cognitive costs of information overload (ScienceDirect, 2024), and the same principle applies to your case archive.
Embrace sensitive adoption search research practices. Parentage cases often involve identifying information that must be handled carefully. A local index — stored on your machine, not in the cloud — keeps this information under your control, reducing privacy risks for the adoptee, the birth family, and yourself.
Plan for the long haul. Unknown parentage cases frequently take a year or more to resolve. Your archive will grow substantially over that period. Periodically review your archive structure — session tags, naming conventions, case identifiers — to ensure that the system remains navigable as it scales. An archive that was well-organized at 200 pages may need restructuring at 2,000. Build that maintenance into your research routine from the beginning.
Your Browser Is Not a Case File
Unknown parentage investigations are too important and too complex to store in browser tabs. Every crash, every session timeout, every platform update is a threat to evidence you may never recover. Indexed sessions transform your browser from a fragile workspace into a durable evidence repository. TabVault captures your research automatically, privately, and searchably — so the next crash costs you a few seconds of re-opening tabs, not weeks of lost work. Join the waitlist and take browser chaos out of your investigations.
The next Chrome crash should cost you five seconds of reopening tabs, not five weeks of reconstructing an evidence chain. TabVault indexes your parentage case research as it happens, so every GEDmatch comparison, every county court record, and every state vital records page is preserved before the browser has a chance to lose it. Researchers working long-duration unknown parentage cases report that the archive becomes indispensable around the four-month mark, when the volume of accumulated sessions exceeds what any spreadsheet or memory can track. At that point, the ability to search six months of cross-platform research in under a second separates cases that stall from cases that resolve.