Private Local Indexing for Sensitive Adoption Search Research
The Privacy Problem Nobody Talks About
A search angel helping an adoptee identify biological parents spends an evening on GEDmatch comparing DNA kits, cross-referencing Ancestry trees, and reviewing county court records. The session produces a cluster of evidence pointing to a specific individual as the likely birth father — a person who may have no idea they have a biological child. That evidence now exists in the search angel's browser history, in her GEDmatch session cookies, and potentially in the cloud sync of her bookmarks and browsing data.
The question is not whether this information is sensitive. It is whether the researcher has adequate control over where it lives.
The 2025 bankruptcy of 23andMe brought genetic data privacy into sharp public focus. The company, once valued at $6 billion, filed for bankruptcy with the genetic data of more than 15 million customers listed as an asset that could be sold. The New England Journal of Medicine noted that no federal law prohibits companies from providing individuals' genetic information to third parties (NEJM, 2025), and HIPAA does not apply to direct-to-consumer genetics companies. State-level protections exist but are inconsistent: the International Association of Privacy Professionals documented how officials from multiple states questioned 23andMe's ability to protect customer data through the bankruptcy process.
For adoption search researchers, the implications are direct. Every cloud service that touches your research data — browser sync, cloud bookmarks, note-taking apps, shared drives — is a potential point of exposure for information that can profoundly affect real people's lives.
Why Adoption Search Data Demands Local Storage
Adoption reunion research privacy is not abstract. The data involved includes biological identities of individuals who may not have consented to being found. It includes information about sealed adoption records, which 16 states have only recently begun to open after decades of legal closure. It includes genetic data that can reveal not just parentage but also health predispositions and ethnic origins.
Sensitive genetic data local storage addresses the core risk: data that never leaves your machine cannot be leaked, sold, or subpoenaed from a third-party server. When your research index lives entirely on your local drive, you control who has access. No cloud provider, no company undergoing bankruptcy, and no data broker can access information that was never transmitted to them.
This matters for DNA match privacy protection specifically because DNA matches reveal information about third parties. When you index a match page showing that Kit #A12345 shares 47 cM with Kit #B67890, you are documenting a genetic relationship between two people — potentially without the knowledge of either one. Storing that documentation locally is a minimum standard of ethical data handling.
Private adoption search indexing also protects the search angel and the adoptee. If cloud-stored research data were accessed by an unauthorized party, the consequences could include premature disclosure of biological relationships, interference with an ongoing search, or emotional harm to individuals who are not ready for contact.
How Private Local Indexing Works
The principle behind confidential genealogy research tools that use local indexing is straightforward: all data capture, indexing, and search happen on your device. No content is transmitted to any external server. No index is synced to the cloud. No search queries leave your machine.
TabVault operates entirely in this local model. When you browse AncestryDNA match pages, GEDmatch results, court records, and vital records portals during an adoption search, the indexer captures the text content of each page and stores it in an encrypted index on your local drive. The turning of chaotic browser sessions into a searchable private database happens entirely within the boundary of your own hardware.
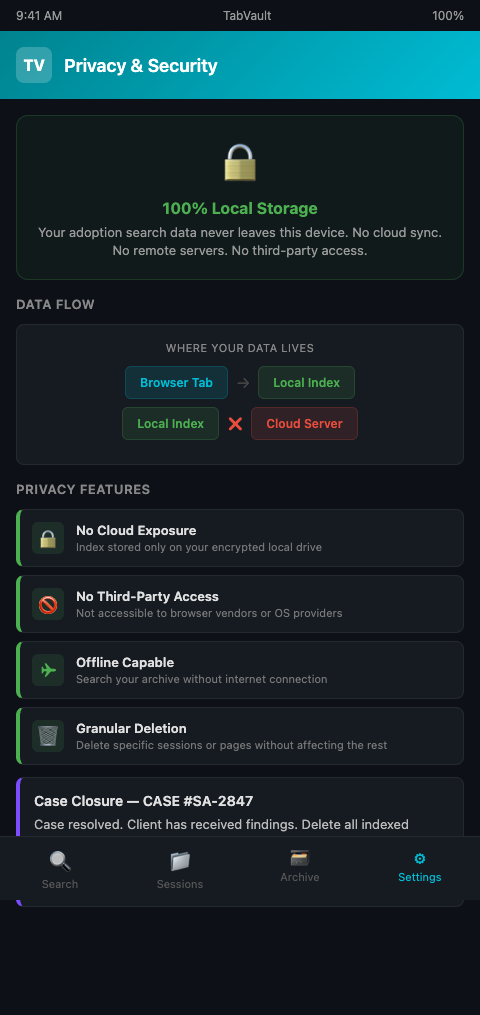
This architecture means:
No cloud exposure. Your research data is not stored on any remote server. A data breach at a cloud provider cannot expose your adoption search evidence.
No third-party access. Unlike browser sync services that may transmit your history and bookmarks to cloud servers, a local index is not accessible to the browser vendor, the operating system vendor, or any other party.
Full researcher control. You decide when to create the index, when to search it, when to back it up (to your own encrypted backup), and when to delete it. The data lifecycle is entirely under your management.
Offline capability. Because the index is local, you can search it without an internet connection. This is useful for researchers who travel to courthouses or archives and want to reference their existing research without connecting to public WiFi.
Granular deletion. When a case concludes, you can delete specific sessions or pages from the index without affecting the rest of your archive. This precision is impossible with cloud-synced browser history, where deletion is typically all-or-nothing. For adoption cases where the adoptee requests that certain information be removed after reunion, the ability to selectively purge specific records from your index is both a practical feature and an ethical safeguard.
Veterinary toxicology researchers handling confidential client records adopt the same private indexing approach for similar reasons — client data and patient records demand the same local-only storage discipline that adoption search research requires.
Operational Security for Adoption Research
Private local indexing is a foundational layer, but complete adoption reunion research privacy requires additional operational practices.
Separate your research profile. Use a dedicated browser profile for adoption search work, distinct from your personal browsing profile. This prevents research data from mingling with personal bookmarks, autofill data, and synced passwords. It also ensures that clearing your research profile's data does not affect your personal browsing.
Encrypt your local drive. A local index is only as secure as the device it lives on. Enable full-disk encryption (FileVault on macOS, BitLocker on Windows) so that if the device is lost or stolen, the index cannot be read without your credentials.
Be deliberate about what you share. When collaborating with other search angels or sharing findings with an adoptee, share specific documents rather than access to your full index. A research published in the Oxford Academic journal on genetic data emphasized that genetic information can reveal details about family members who never consented to testing (Oxford Academic, 2023). Every piece of data you share has the potential to affect individuals beyond the person you are sharing with.
Plan for case closure. When an adoption search concludes — whether successfully or not — decide what happens to the indexed data. Delete it if the case is closed and the adoptee has the information they need. Archive it securely if there is a possibility the case will reopen. Do not leave sensitive data sitting in an unmonitored index indefinitely.
Document your privacy practices. If you work with organizations like DNAngels or the Volunteer Search Network, your privacy practices should align with their policies. Having a clear description of how you store and protect research data builds trust with adoptees and with the organizations that connect you.
For researchers using the same indexed sessions for adoption search evidence and vital records, the privacy framework must cover both DNA data and documentary records — birth certificates, court orders, and hospital records all carry the same sensitivity.
The stakes of a privacy failure in adoption research are not abstract. Premature disclosure of a biological relationship can disrupt families, damage trust between the adoptee and the search angel, and in some cases trigger legal consequences if sealed records were accessed through improper channels. The Adoptees United legislative tracker shows that adoptee access laws vary dramatically by state, and what is legally accessible in one jurisdiction may be sealed in another. A local index that never transmits data externally ensures that your research remains compliant with the most restrictive applicable standards, regardless of which state's records you are working with.
Audit your existing digital footprint. Before switching to local-only indexing, review your current research environment for privacy gaps. Are your Ancestry or GEDmatch sessions being captured by browser sync? Are your bookmarks stored in a cloud account? Are your research notes in a shared Google Doc? Each of these channels represents a potential exposure point for adoption search data. Migrating to a local-only workflow starts with identifying and closing these existing gaps.
Privacy Is Not Optional in This Work
Adoption search research sits at the intersection of genetic science, family law, and deeply personal human questions. The data you handle during an investigation can change lives — for better or for worse — depending on how it is managed. Private local indexing is not a luxury feature; it is a baseline ethical requirement for anyone working with sealed records, biological identities, and genetic data. TabVault keeps your entire research index on your own machine, searchable and secure, with no data ever leaving your device. Join the waitlist and give your adoption search cases the privacy protection they demand.
For researchers who will eventually share findings with reunion registries, starting with a private local index ensures you maintain full control over what gets shared and with whom.