Why Genetic Genealogists Lose Critical Matches Between Sessions
The Vanishing Match Problem
A genetic genealogist working an unknown parentage case logs into GEDmatch on a Tuesday evening and identifies a promising cluster of one-to-many matches sharing segments above 30 centimorgans. She screenshots a few, bookmarks one, and plans to continue Wednesday. By Wednesday, one match has opted out of GEDmatch Genesis, another has deleted their kit, and the GEDmatch results she saw the night before have shifted because a new batch of uploads recalculated the one-to-many list. The trail she was following has fractured.
This is not a rare edge case. GEDmatch hosts over 1.5 million genetic profiles, and its database changes daily as users upload, delete, and modify kits. AncestryDNA, with more than 27 million tested customers, refreshes match lists whenever its algorithm updates or new kits enter the system. A match page you viewed on Monday may display different shared matches, different trees, or different centimorgan totals by Friday.
Losing DNA matches between sessions is not a matter of carelessness. It is a structural consequence of doing research on dynamic, third-party platforms that prioritize current state over historical state. No genealogy testing company maintains a changelog of what your match list looked like last week. FamilySearch, which hosts over 14.3 billion searchable records, is more stable for documentary records — but even there, record collections are updated, re-indexed, and occasionally reorganized without advance notice to individual researchers.
Why Sessions Break and Research Disappears
Three distinct forces cause cross-session research loss in genetic genealogy.
Platform volatility. Testing companies update their databases and algorithms on their own schedules. Ancestry rolled out a new matching algorithm in early 2024 that recalculated centimorgan totals and pruned low-confidence matches. Researchers who had been tracking specific distant matches found those matches had dropped below the 20 cM display threshold overnight — not because the DNA changed, but because the math did.
User-side deletion. The 23andMe bankruptcy in 2025 prompted millions of users to delete their data, with attorneys general from multiple states urging customers to protect their genetic privacy (NPR, 2025). Every deleted kit removes a node from the match network. If that node was a key triangulation point in your investigation, the gap cannot be reconstructed from memory.
Browser impermanence. Carnegie Mellon researchers documented that about 25% of study participants experienced browser or computer crashes because they had too many tabs open (Carnegie Mellon University, 2021). For genealogists running 50 or more tabs across Ancestry, GEDmatch, FamilySearch, and newspaper archives, a single crash can wipe out an entire evening's research context in seconds.
These three forces compound each other. You lose the tab in a crash, then discover the platform changed the data before you could re-open it, and meanwhile the match owner has adjusted their privacy settings. The result is a permanent gap in your case file.
The compounding effect is worst in the early stages of an investigation, when the researcher is casting a wide net and reviewing dozens of matches to identify patterns. At this stage, every match page is potentially significant, but no individual page has been flagged as critical yet. Losing access to a batch of pages from this exploratory phase means losing the raw material from which the case hypothesis was formed — and reconstructing that raw material requires repeating work that may no longer be possible if the underlying data has shifted.
Turning Session Tracking Into a Safety Net
The antidote to cross-session research loss is treating every browser session as a collection event rather than a temporary workspace. This means turning chaotic browser sessions into a searchable private database where every page you visit is indexed locally, preserving its content independent of what happens on the source platform.
TabVault does exactly this for genetic genealogy session tracking. As you browse AncestryDNA match pages, GEDmatch one-to-many results, and FamilySearch records, each page is indexed in a local, private archive. When you close the tab — deliberately or by crash — the content remains searchable. When the platform updates its algorithm and your match list changes, your archived version preserves what you saw during your original session.
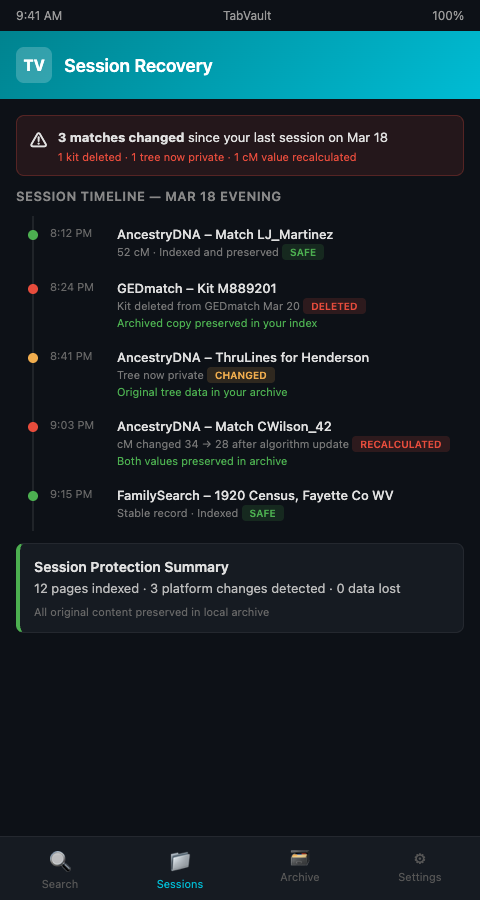
This matters most for unknown parentage case management, where the research timeline can stretch across months or years. A case that began with a GEDmatch cluster in January may not reach resolution until August, and during those seven months every platform involved will have changed its data multiple times. Session-level indexing gives you a longitudinal record: not only what matches exist today, but what matches existed on January 14 when you first identified the cluster.
The longitudinal dimension is particularly powerful for tracking match deletions. When a kit disappears from GEDmatch or Ancestry, the platform gives no notification and no explanation. Without an archived session, you may not even realize the match existed. With one, you have a record of the match's kit number, centimorgan value, shared segments, and any tree information that was visible — data that can still contribute to your analysis even after the live match is gone. In adoption search work, where every match node matters, this preservation is the difference between a viable investigation and a dead end.
The same principle applies to saving discoveries that researchers often overlook. Shared segment data, one-to-many result sets, and triangulation group memberships are all ephemeral unless you actively preserve them. An indexed session captures these details as part of the page content, no manual copying required.
The indexed session also simplifies collaboration. When you share findings with another search angel or hand off a case, your archived sessions provide a complete record of what you reviewed, when you reviewed it, and what the platform showed at the time. The recipient does not need to trust your memory — they have the indexed pages themselves.
Investigative podcast producers face a parallel challenge — sources disappear, pages get taken down, and digital evidence evaporates between recording sessions. Their strategies for preserving connections that browser history erases map directly onto the genealogist's need for durable session records.
Preventing Loss at Scale
Once you commit to indexing every research session, consider these practices to maximize the value of your archive.
Index before you analyze. Start each session by opening your target pages and letting them index before you begin clustering or note-taking. If a match page takes 30 seconds to load and index, that is 30 seconds of insurance against every failure mode described above. This order of operations — index first, analyze second — also ensures that your archive contains the complete, unfiltered page content rather than only the portions you decided were important during initial review.
Build redundancy for critical matches. For the handful of matches that form the core of your case hypothesis, index the page multiple times over the course of the investigation. An index from January and another from April create a before-and-after record that documents how the match's data changed over time — changes that may themselves be analytically significant.
Capture GEDmatch results in full. GEDmatch one-to-many results are sorted by total centimorgan value, and the default view shows only the top matches. Scroll to the bottom — or adjust the display threshold — before the page indexes. A partial index misses the most distant matches that often hold the breakthrough clue in unknown parentage work.
Cross-reference session timestamps. When your archive preserves the date of each indexed page, you can compare what AncestryDNA showed on two different dates. This diachronic view is a genuine analytical tool: if a match appeared in March but vanished by June, you know the kit was deleted or fell below a recalculated threshold. That absence is itself evidence worth documenting.
Separate active cases. A report by the International Association of Privacy Professionals highlighted how intermingled data creates confusion in evidence-intensive work (IAPP, 2025). Apply the same logic to your own archive: tag or segment sessions by case so that a search for "Martinez" in Case A does not surface noise from Case B.
Document what changed, not only what exists. When you notice that a match has disappeared or that a shared-match list looks different from your archived version, record that discrepancy. The Board for Certification of Genealogists standards require resolution of conflicting evidence, and a match that was present in March but absent in June is a data point — not just an annoyance. Your archived session provides the "before" snapshot that makes this kind of analysis possible. Without it, you would never know what changed.
Your Matches Deserve Better Than Browser Memory
Genetic genealogy research is cumulative, fragile, and irreplaceable. Every match you review, every shared segment you evaluate, every tree you inspect represents analytical work that cannot be perfectly repeated once the underlying data changes. Stop trusting your browser to remember what the platforms will not. TabVault indexes your research sessions locally and privately so that no crash, no algorithm update, and no deleted kit can erase your progress. Join the waitlist and protect the matches that matter most to your cases.
Consider what happens the next time a GEDmatch kit vanishes from your one-to-many results overnight. Without an indexed archive, the match is gone and so is every data point it carried. With TabVault running during your sessions, that kit's centimorgan total, shared segments, ancestral surnames, and contact email are already preserved in your local index. Researchers on the waitlist typically build an archive spanning three to five DNA platforms within their first month, and by week ten they report catching cross-platform connections they would have missed entirely. Your session history transforms from a disposable browser artifact into a durable investigative asset that no platform change can erase.