5 GEDmatch Discoveries Most Researchers Forget to Save
5 GEDmatch Discoveries Most Researchers Forget to Save
The Data That Slips Through
GEDmatch is one of the few platforms where genetic genealogists can perform cross-company comparisons, running an AncestryDNA kit against a 23andMe kit or a FamilyTreeDNA kit within a single interface. That flexibility generates a staggering volume of intermediate results — and almost none of it is automatically preserved. GEDmatch hosts over 1.5 million profiles, and each one-to-many comparison can produce pages of match data that exist only as long as your browser tab stays open.
A 2022 survey from BigDATAwire found that 80% of workers experience information overload, up from 60% in 2020. Genetic genealogists are no exception. When you are deep in a one-to-many result set at 11 p.m., triaging matches by centimorgan threshold and comparing ancestral surnames, the last thing on your mind is methodical data preservation. But the GEDmatch discoveries you skip over tonight may be the ones your case needs six months from now.
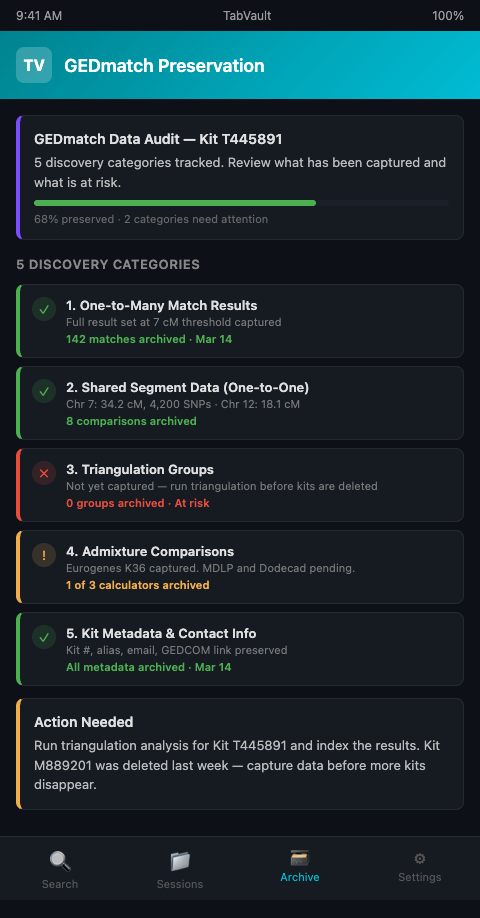
Here are the five categories of GEDmatch data that researchers most commonly fail to preserve — and why each one matters.
1. One-to-Many Match Result Sets
The one-to-many tool is usually the first stop on GEDmatch. It compares your kit against the entire database and returns a ranked list of matches sorted by total shared centimorgans. Most researchers scan the top matches, note the strongest hits, and move on. The full result set — including the distant matches at 15, 10, or 7 cM — gets abandoned.
Those distant matches matter. In unknown parentage cases, the breakthrough often comes not from the closest match but from a pattern among several distant ones. If five unrelated matches all list a common ancestral surname or geographic origin, that cluster points toward a specific family line. But you can only see that pattern if you have the full one-to-many results available for comparison.
The default GEDmatch display may not show all matches. Adjusting the centimorgan threshold documentation to lower the display cutoff — some researchers go as low as 7 cM — reveals matches that the default view hides. The ISOGG wiki on autosomal DNA match thresholds explains how each platform applies different minimum thresholds, and GEDmatch gives you the control to set your own. Capture the full result at your chosen threshold before closing the tab. Applying tab indexing to your GEDmatch workflow makes this capture automatic rather than manual.
2. Shared Segment Data From One-to-One Comparisons
After identifying promising matches in the one-to-many list, most researchers run one-to-one comparisons to see exactly which chromosomal segments they share. GEDmatch displays the start and stop positions, segment size in centimorgans, and the number of matching SNPs for each shared segment. This shared segment data preservation is critical for triangulation — the process of confirming that three or more people share the same segment inherited from a common ancestor.
The problem is that researchers often glance at the chromosome browser visualization, confirm the match looks legitimate, and move on without preserving the numerical data. A month later, when they need those exact segment boundaries to compare against a new match, the one-to-one result has to be regenerated — assuming the other kit still exists in the database.
3. Triangulation Group Memberships
GEDmatch's triangulation tools identify groups of matches who all share overlapping segments on the same chromosome. A triangulation group is strong evidence that those individuals descend from the same ancestor through the same line. Documenting these groups is foundational to the Genealogical Proof Standard maintained by the Board for Certification of Genealogists, which requires thorough analysis and correlation of all evidence.
Triangulation results are among the most time-consuming to regenerate because they depend on the specific combination of kits present in the database at the time you run the analysis. Remove one kit from the group, and the triangulation may no longer hold. Save the results when you first generate them.
4. Admixture and Ethnicity Comparisons
GEDmatch Genesis research tips often focus on the platform's admixture calculators, which estimate ancestral population composition using different reference panels. While admixture results are not direct evidence of specific ancestors, they provide contextual clues — especially when comparing your results across multiple calculators (Eurogenes, MDLP, Dodecad) to see which populations appear consistently.
Researchers run these calculators once, note the general results, and rarely preserve the full output. But when a case stalls months later and you need to distinguish between two candidate family lines — one with documented Scandinavian ancestry and one with documented Iberian ancestry — having your archived admixture comparisons immediately available saves hours of re-running calculators and re-interpreting results.
5. Kit-Level Metadata and Contact Information
GEDmatch displays metadata for each kit: the kit number, the email address of the uploader (if the user has opted to display it), the alias or name associated with the kit, and the GEDCOM tree link if one is attached. This information is the connective tissue of collaboration. When you need to reach out to a match six months after first encountering their kit, that email address or kit number is what makes contact possible.
Kit metadata disappears when a user deletes their account or changes their settings. There is no platform notification that a match's contact information has changed. The only reliable record is the one you made during your session.
The 2025 bankruptcy of 23andMe, which put the genetic data of over 15 million users in legal limbo, demonstrated what happens when an entire platform's metadata becomes inaccessible. Researchers who had recorded kit numbers, email addresses, and shared segment data from their 23andMe sessions retained the ability to contact matches and reference prior comparisons. Those who had not lost access to years of accumulated match metadata in a single corporate event. GEDmatch is a smaller platform with a different ownership structure, but the lesson applies universally: metadata that lives only on the platform lives on borrowed time.
Why These Five Categories Matter More Than Others
Other GEDmatch outputs — admixture oracle results, phasing visualizations, relationship predictions — have analytical value but tend to be interpretive rather than evidentiary. The five categories above are different because they contain raw data points: kit numbers, centimorgan values, segment boundaries, population percentages, and email addresses. These are the building blocks of a proof argument. Lose a relationship prediction, and you can regenerate it from the underlying data. Lose the underlying data — the segment boundaries, the kit metadata, the triangulation membership — and you may not be able to regenerate anything.
The Board for Certification of Genealogists standards require analysis and correlation of all evidence contributing to a conclusion. In genetic genealogy, "all evidence" includes the raw GEDmatch outputs that most researchers treat as intermediate work product. When these outputs are preserved in a searchable archive, they become citable sources in a proof argument — not just notes on a scratch pad.
How Indexing Solves the Preservation Problem
Each of these five discovery types exists as browser-rendered text. A tab indexing system captures that text automatically, turning chaotic browser sessions into a searchable private database where every GEDmatch result is preserved in a local archive. Instead of manually copying kit numbers into spreadsheets or screenshotting one-to-many results, you let the indexer capture the page content as part of your normal workflow.
TabVault turns this process into a background operation. Browse GEDmatch as you normally would — run one-to-many comparisons, check one-to-one segments, view triangulation results — and every page is silently indexed. When you need those shared segment boundaries three months later, you search your archive for the kit number and retrieve the full one-to-one comparison from the session where you first ran it. The data lives in your evidence log rather than in a tab you closed weeks ago.
This same discipline applies to building personal toxin reference libraries from browser sessions in veterinary toxicology — the principle of capturing ephemeral web data into a durable, searchable index is universal.
The combination of all five discovery types in a single searchable archive is what makes the approach powerful. A search for a kit number retrieves the one-to-many result where you first encountered it, the one-to-one comparison you ran, the triangulation group it belonged to, and the contact metadata associated with the kit — all from different GEDmatch pages, all surfaced in one query. This cross-referencing within your own research history would require hours of manual reconstruction without an index. With one, it takes seconds.
Preserve the Data Your Future Self Will Need
GEDmatch gives researchers extraordinary analytical power, but it stores nothing on your behalf. Every one-to-many result, every shared segment comparison, every triangulation group exists only as long as the underlying kits remain in the database and your browser tab stays open. The five discovery types above are the ones that researchers most consistently fail to save and most frequently need later. TabVault indexes them automatically, building a permanent archive from your GEDmatch sessions. Join the waitlist and stop losing the discoveries that matter most to your cases.