Detecting Patterns in DNA Match Clusters Across Months of Sessions
The Pattern That Takes Six Months to See
A genetic genealogist reviewing her AncestryDNA match list in January spots a new third cousin with 90 centimorgans of shared DNA. She notes the match, checks the shared matches, and moves on. In April, two more matches appear in the same centimorgan range, sharing several of the same people on their shared match lists. By August, a fifth match surfaces, and suddenly the cluster snaps into focus: all five descend from the same ancestral couple in rural Kentucky, circa 1870. The answer was always there, but it took six months of accumulating matches before the pattern became visible.
This is the fundamental challenge of long-term genetic genealogy research. The National Genealogical Society describes DNA clusters as groups of matches who likely share the same common ancestor, but building those clusters is not a one-session task. New matches trickle in as more people test. Existing matches update their trees. The researcher's own understanding of the family structure evolves. DNA match cluster pattern detection requires continuity across months of separate research sessions.
The problem is that browsers do not provide continuity. Each session exists in isolation. The researcher who noticed that first match in January has no efficient way to connect it to the matches she finds in April and August unless she maintained a separate spreadsheet or notebook outside the browser. And spreadsheets capture what the researcher chose to record, not the full context of what she actually viewed and investigated during each session.
The scale of the problem grows with the size of the DNA database. AncestryDNA alone has tested over 25 million people, and the database continues to grow. Each new tester creates new matches for existing users, which means the match list a researcher reviewed in January is not the same list she will see in August. New matches appear, existing matches update their trees, and the cluster picture shifts incrementally. A researcher who does not have access to her January session context when reviewing August data is effectively starting from a partial picture every time she sits down.
Building a Long-Range Cluster Detection System
TabVault reframes the cluster analysis problem by turning chaotic browser sessions into a searchable private database that accumulates context over time. Every page visited during a DNA match review session, including match profiles, shared match lists, chromosome browsers, and linked family trees, becomes part of a persistent, full-text-searchable archive. When a new match appears in August, the researcher does not need to remember what she found in January. She searches for the shared surname, the geographic location, or even a centimorgan value, and the archive surfaces every related session from the past six months.
This is how cluster analysis across sessions actually works in practice. The researcher who has been organizing DNA cluster analysis research across a long-running case builds a cumulative picture that no single session could reveal. Each monthly review adds new data points to the archive. Patterns emerge not from any one session but from the intersection of dozens of sessions spanning weeks or months.
The practical workflow looks like this: the researcher conducts her monthly DNA match review, visiting new match profiles and exploring shared matches on AncestryDNA, MyHeritage, or FamilyTreeDNA. TabVault indexes every page visited. Two months later, when she reviews the next batch of new matches, she runs a search against her archive before starting fresh research. The search reveals that the new match shares a surname and a geographic cluster with matches she investigated previously. Instead of duplicating two hours of work, she picks up where the earlier sessions left off.
The value compounds over time. A researcher in her first month of working a case has a thin archive. By month six, the archive contains every match profile viewed, every shared match list examined, every tree branch explored, and every vital record accessed. Each new session is checked against this growing body of prior research, and the probability of finding a meaningful connection to past work rises with every month. The archive becomes a pattern detection instrument that improves as it accumulates data.
A concrete example: a researcher investigating an adoptee's paternal line reviews a new 85-centimorgan match in October. She searches TabVault for the match's surname and gets no results. She searches for the match's listed location, "Boone County, Missouri," and the archive returns three sessions from July where she was researching a different match who also had ancestors in Boone County. Those two matches, investigated three months apart, share no obvious tree connection and do not appear on each other's shared match lists. But the geographic overlap suggests they may descend from the same Boone County family through different lines. Without the archive connecting those sessions, the geographic pattern would remain invisible.
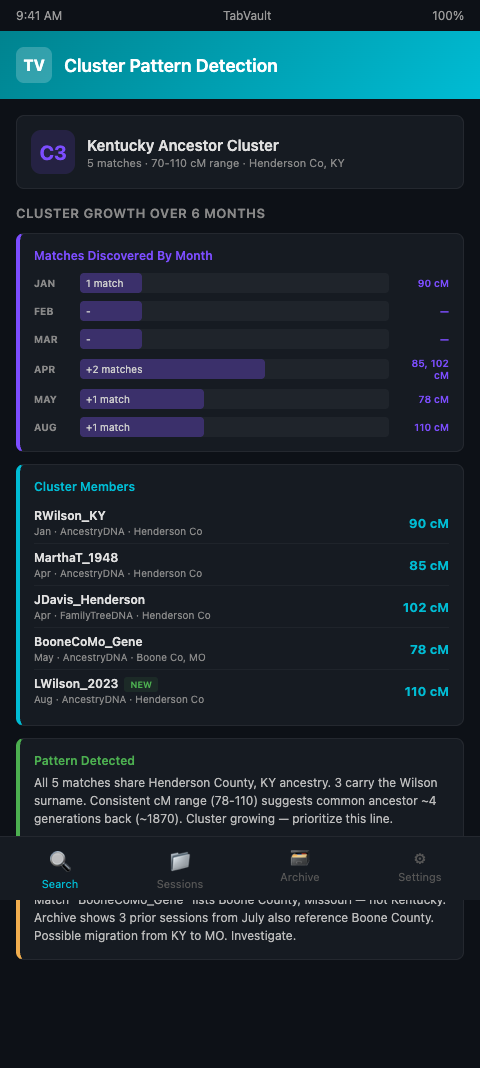
This workflow directly addresses monthly DNA match review patterns. Most researchers follow a cycle: new matches appear, they review them, they note connections, and they move on. But each cycle is disconnected from the last. The archive bridges those gaps. A search for "Henderson County Kentucky" returns results from January, April, and August in a single view, making the cluster visible without the researcher having to reconstruct it from memory.
The Carnegie Mellon University study on browser tab behavior found that people often keep tabs open as external memory aids because they fear losing access to information. Genetic genealogists are especially prone to this pattern, holding onto match profile tabs for weeks in hopes of spotting a connection later. TabVault eliminates the need for that workaround by making every visited page permanently retrievable.
Advanced Pattern Detection Across Large Match Sets
The first advanced tactic is combining TabVault's full-text search with centimorgan threshold tracking. When a researcher notices that four matches in a cluster all share between 70 and 110 centimorgans, she can search the archive for sessions where she investigated matches in that range. The search may reveal additional matches she investigated months ago but did not immediately connect to the cluster, because at the time only one or two members were visible.
The second tactic is geographic pattern detection. Genetic genealogy data patterns often manifest as geographic clusters before they manifest as surname clusters, because maiden names change with each generation but locations are stickier. A researcher working pattern detection in long-running investigations across podcast source material uses the same principle: search for the location, and the people connected to it reveal themselves.
The third tactic addresses the false cluster problem. Not every group of shared matches represents a meaningful ancestral connection. Endogamous populations, where intermarriage within a community inflates shared DNA values, can produce clusters that look significant but actually reflect community-wide relatedness rather than a specific common ancestor. Research from the International Society of Genetic Genealogy documents how endogamy complicates adoption searches specifically. The researcher who has six months of indexed sessions can compare a suspected false cluster against her archived research to determine whether the shared matches also appeared in other, unrelated clusters, a strong indicator of endogamy rather than a true ancestral connection.
The fourth tactic involves tracking cluster evolution over time. A cluster that contained three matches in February and seven matches by September is growing, which means more people in that ancestral line are testing. This growth rate signals where the researcher should focus attention next, because a fast-growing cluster is more likely to produce the close match that breaks the case open. The session archive makes this trend visible by showing the density of sessions dedicated to a particular cluster at different points in the investigation.
The fifth tactic is documenting dead-end clusters. Not every cluster leads somewhere productive. Some produce matches whose trees are private or nonexistent. Some lead to family lines that dead-end in immigration with no further records available. Documenting these dead ends in the session archive prevents the researcher from reinvestigating them when a new match that appears to belong to the same cluster shows up three months later. The archive shows that the cluster was already investigated and what specifically blocked further progress.
Finally, researchers should build a habit of running retrospective searches at the start of each monthly review session, not just at the end. The most productive pattern detection happens when new data is immediately checked against the full archive, before the researcher invests time in ground-up investigation that the archive has already partially completed. This pre-session search takes two to three minutes and regularly surfaces connections that would otherwise take hours of redundant research to rediscover.
Cross-Platform and Documentation Considerations
A sixth consideration applies to researchers who work across multiple DNA testing platforms simultaneously. A match cluster may span AncestryDNA, MyHeritage, and FamilyTreeDNA, with different matches from the same ancestral line appearing on different platforms. Platform-native clustering tools only see matches within their own database. TabVault's indexed archive spans all platforms visited during research, making cross-platform cluster detection possible. A surname that appeared on an AncestryDNA match profile in January and on a FamilyTreeDNA match profile in June becomes visible as a pattern only when both sessions are searchable from the same archive.
Researchers should also consider the documentation value of long-term cluster tracking. When a case reaches its conclusion and the researcher prepares a report, the archived sessions provide a timeline showing how the critical cluster emerged over months. This timeline demonstrates methodical, thorough research rather than a lucky find. For forensic cases subject to professional review, this documented pattern detection history strengthens the credibility of the final conclusion.
See Patterns Your Spreadsheets Miss
Genetic genealogy data patterns only reveal themselves to researchers who can see across months of accumulated sessions. TabVault builds that long-range visibility into your browser workflow. Join the waitlist to start detecting the clusters that single-session research will never find.
DNA match clusters do not announce themselves in a single session. They reveal themselves slowly, over months, as new testers appear and existing matches update their trees. TabVault is built for exactly this kind of long-horizon pattern detection. Each monthly match review you conduct adds another layer of indexed data to your archive, and a pre-session search against that growing archive regularly surfaces geographic overlaps, surname recurrences, and centimorgan-range patterns that no single review could reveal. Researchers who have tracked clusters across six or more months of indexed sessions describe the archive as the difference between guessing at connections and seeing them confirmed through accumulated evidence.