Detecting Source Patterns Across Long-Running Investigation Arcs
Patterns That Only Appear at Scale
The ICIJ's Panama Papers investigation used Neo4j graph databases to identify hidden relationships across 11.5 million documents — connections that were invisible when analysts examined individual files but obvious once the data was queryable as a unified corpus (Neo4j / ICIJ). Investigative podcast producers face the same structural challenge at a different scale. A show tracking a local corruption story across three seasons might accumulate 2,000 indexed web pages spanning county records, court filings, corporate registrations, and news coverage. The patterns in that material — a name that appears in property transfers six months apart, a corporate address shared by three seemingly unrelated LLCs, a series of permit applications filed within the same two-week window — are the signals that advance the investigation. But they only surface when the full research archive is searchable.
Investigative Reporters and Editors emphasizes that database analysis and document cross-referencing are foundational skills for modern investigative work, with their training programs specifically covering how to detect patterns in public records that single-document review would miss (IRE). The problem for podcast producers is not methodology — it is infrastructure. They know what patterns to look for. They lack a searchable archive deep enough to reveal them.
Long-running investigation research patterns tend to cluster around three types: entity recurrence (the same person or company appearing in unrelated contexts), temporal correlation (events happening in suspicious proximity), and geographic overlap (addresses or jurisdictions connecting otherwise separate threads). All three require searching across months or years of accumulated research — exactly the capability that browser tabs, bookmarks, and spreadsheets cannot provide.
The GIJN's top investigative tools coverage documents a growing category of analysis platforms — Graphext, Datashare, and others — specifically designed to detect hidden patterns in large datasets. But these specialized tools assume structured data: spreadsheets, databases, or document collections that have been cleaned and formatted for analysis. The raw material of podcast investigation research is unstructured by nature — web pages, PDFs, dynamic database results, news articles — and it enters the archive in whatever format the browser renders it. The research pattern detection tool that matters most is the one that works on unstructured, full-text data accumulated over time.
Turning Accumulated Research Into a Pattern Detection Tool
The fundamental shift is treating your research history as a dataset rather than a reference library. A reference library lets you retrieve a specific document you remember. A dataset lets you query for relationships you have not yet imagined. This is what turning chaotic browser sessions into a searchable private database makes possible: every page you visit during an investigation session becomes a row in a searchable corpus that grows richer with every episode cycle.
TabVault indexes the full text of every page a producer visits — county assessor lookups, Secretary of State filings, court docket searches, local news articles, campaign finance disclosures. After two seasons of a show, that index might contain 3,000 pages spanning 18 months of research. A search for a person's name returns the pages where that name appears, the dates those pages were indexed, the source domains, and the surrounding text. Detecting source patterns across an investigation becomes a matter of querying the archive instead of relying on a producer's memory.
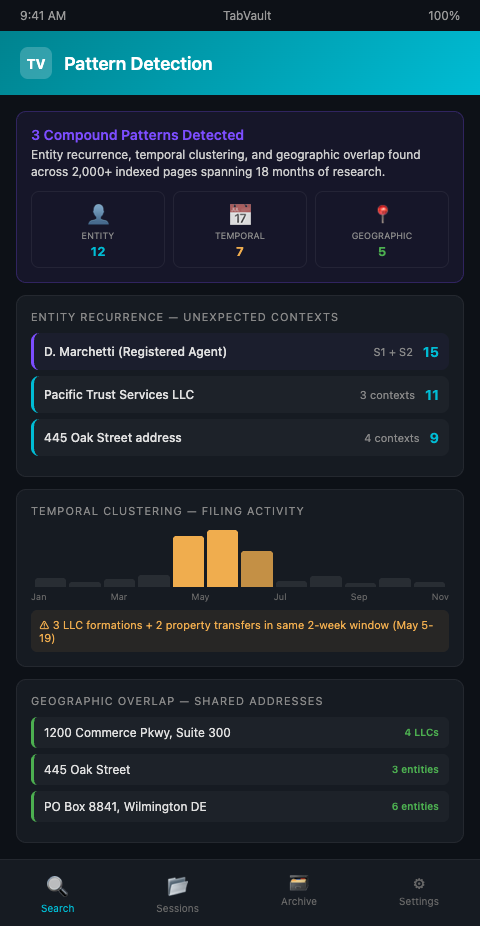
Consider a concrete example. In Season 1, a producer researches a city council member's voting record on zoning changes. Several property LLCs appear in the public comments for those zoning hearings. In Season 2, a different producer investigates a construction company that received a no-bid contract from the same city. When the team searches their TabVault archive for the construction company's registered agent, they discover the name appeared in a Season 1 property LLC filing — a connection that spans eight months of research and two different editorial threads. No one remembered the Season 1 reference. The search surfaced it — pattern recognition public records work that the archive performs automatically when the right query is run.
This type of investigation arc source analysis depends on continuity. The archive must survive producer turnover, season breaks, and hardware changes. TabVault's local index persists independently of browser state — closing tabs, clearing history, or switching machines does not destroy the indexed content. The research from Session 1 is as searchable as the research from Session 200. Teams that maintain investigation continuity protocols protect this accumulated value against the organizational disruptions that occur during multi-year investigations.
Pattern recognition in public records also benefits from temporal search. When a producer suspects that a series of property transfers were coordinated, searching the archive by date range reveals whether related pages were filed or indexed within the same window. The timeline building capability that TabVault provides turns date-stamped index entries into a visual chronology of the investigation's evidentiary trail.
The depth of the archive determines the sophistication of the patterns it can reveal. After one month, the archive might show entity recurrence — the same LLC appearing in two contexts. After six months, it might show temporal correlation — filing dates clustering around key events. After two years, it might show systemic patterns — a network of related entities engaging in the same type of transaction repeatedly across multiple jurisdictions. Each layer of pattern complexity requires a deeper archive, which is why the indexing habit must start at the beginning of the investigation instead of being retrofitted later.
Investigation arc source analysis also benefits from what might be called "background radiation" — the pages a producer indexes while not actively pursuing a lead. A news article indexed during a general background research session might contain a name that becomes significant three seasons later. The archive captures this background material alongside the targeted research, and both are equally searchable. The patterns that emerge from background radiation frequently produce the investigation's strongest narrative beats — a name that appeared in a minor news article during week two becoming the central figure in a fraud case revealed during month fourteen.
Advanced Pattern Detection Strategies
Run periodic "entity audits." Every two weeks, search the archive for every named entity in the current investigation — every person, company, address, and phone number. Cross-reference the results against the team's working entity list. New appearances of known entities in unexpected contexts are the highest-value pattern signals.
Search for addresses, not only names. People use aliases. Companies rebrand. But physical addresses change less frequently. Searching for a street address across the full archive reveals connections between entities that appear unrelated by name. A registered agent office, a property address, or a P.O. box shared by multiple targets is a structural connection that name-based research misses.
Compare filing dates across jurisdictions. If a corporate registration in one county was filed the same week as a property transfer in another county involving the same principals, that temporal correlation may indicate coordinated activity. TabVault's date-stamped index entries make these correlations searchable. The same approach applies to the form of pattern detection used in genealogical research, where temporal clustering of records reveals hidden relationships.
Build "negative searches" into your routine. Sometimes the pattern is an absence. If a company that appears in 15 indexed pages across two seasons has zero mentions in local news coverage, that absence is itself a data point. Search for expected references and note what is missing. Gaps in the public record are where the story lives.
Archive the search queries themselves. Keep a log of every search you run against the archive, along with the number of results and any notable findings. Over time, this query log becomes a meta-layer of the investigation — a record of what you were looking for, when, and what you found. It also prevents redundant searching across team members.
Layer pattern types for compound signals. The strongest investigative signals combine multiple pattern types. An entity that recurs across contexts (entity recurrence), with filing dates that cluster around a political event (temporal correlation), and with shared addresses in a single office park (geographic overlap) presents a compound pattern that is far more significant than any single signal. Train yourself to search for one pattern type and then immediately test for the others.
Set pattern detection milestones in your production calendar. Schedule formal pattern-detection sessions at the end of each production month — dedicated time to run entity, address, and date-range searches against the full archive. These sessions should produce a written summary of newly detected patterns, which feeds into the editorial planning process. Treating pattern detection as a scheduled activity instead of an ad hoc practice ensures that the archive's compound value is actually extracted on a regular basis. The McKinsey Global Institute found that searchable records of knowledge can reduce the time employees spend searching for internal information by up to 35 percent — and pattern detection milestones are the mechanism through which investigative teams capture that efficiency gain.
Stop Trusting Memory to Find Connections
Human memory is unreliable across multi-season investigations. A research pattern detection tool built from indexed browsing sessions catches the connections that producers forget, overlook, or never knew existed. TabVault turns your accumulated research into a queryable corpus where detecting source patterns across an investigation becomes a systematic practice instead of an accident. If your investigation has outgrown your ability to hold it in your head, join the waitlist and let the archive do the pattern recognition.
After two seasons tracking a local government corruption story, one production team's TabVault archive held 3,200 indexed pages spanning county records, court filings, and corporate registrations. A routine entity audit in month fourteen revealed that a registered agent name from a Season 1 property LLC filing matched a construction company officer discovered in Season 2 -- a connection buried across eight months and two editorial threads. That pattern, invisible to any single producer's memory, drove the next three episodes. Join the waitlist and let your accumulated research reveal the patterns that memory alone cannot hold.