Building Episode Timelines From Months of Indexed Sessions
The Timeline Problem in Long-Form Investigation
Sarah Koenig spent roughly a year researching the first season of Serial, and the podcast format allowed her to release findings as they developed. MIT's Docubase documented how the show's investigative structure relied on assembling a precise chronology of events from documents, interviews, and records gathered over months. For producers working on investigations of similar scope, the timeline is not a nice-to-have -- it is the structural skeleton of every episode.
The Bureau of Justice Statistics has tracked felony case processing through state courts since 1988, documenting how cases move from filing through disposition across timelines that often stretch beyond twelve months. Those same filing-to-disposition timelines are the raw material that podcast producers need to reconstruct for their narratives. The challenge is that the dates needed for episode timeline construction live in different systems and arrive at different times. A court docket shows filing dates from 2018. A newspaper archive reveals a story published in 2019 that references events from 2017. A FOIA response arriving in 2024 contains emails from 2020. Each of these dates matters for the narrative, and each was discovered during a different browser research session, potentially weeks or months apart.
A producer working on a police misconduct series described the problem bluntly: she had dates scattered across handwritten notes, bookmarked tabs, screenshots, and text files. When she tried to assemble the episode timeline, she spent three days just reconciling her own records before she could begin writing. Half of those dates required re-verifying because she could not remember which source they came from.
From Browsing Sessions to Chronological Backbone
The raw material for investigation timeline building already exists in your research sessions. Every court docket page displays filing dates. Every newspaper article carries a publication date. Every FOIA document has a timestamp. Every corporate filing shows a registration or amendment date. The problem is not that the dates are missing -- the problem is that they are trapped in browser sessions that no longer exist.
TabVault addresses this by turning chaotic browser sessions into a searchable private database where every date-bearing page you visited remains accessible. When you need to construct an episode timeline, you search your indexed sessions for the subject's name and scan the results chronologically. The court filing from session one, the news article from session four, and the FOIA document from session twelve all appear together, each carrying its original dates.
The podcast timeline from browsing sessions builds itself as you research. You do not need to maintain a separate timeline document during the research phase -- though you certainly can. The indexed sessions serve as the raw chronological record, and the timeline emerges when you query them.
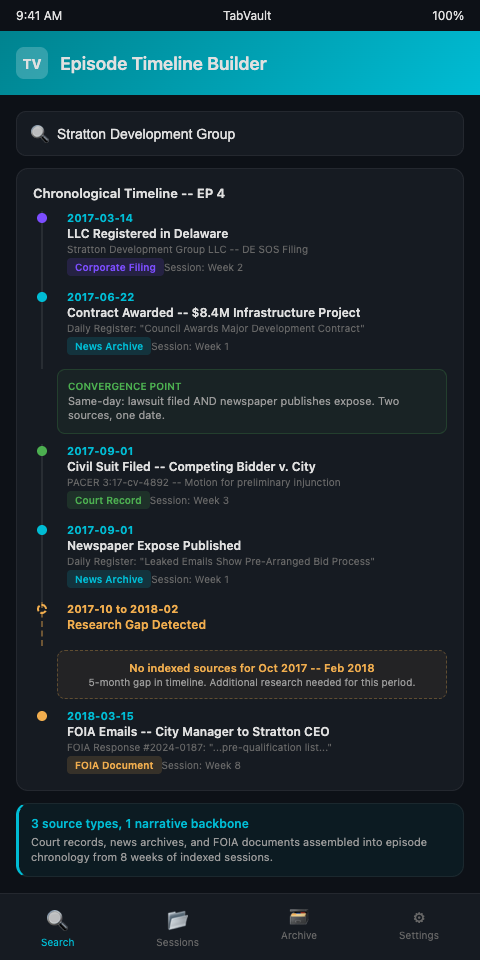
Producers who have been linking FOIA responses to news archive discoveries across episodes already have the building blocks. FOIA documents carry government-side dates. News archives carry publication-side dates. Court records carry judicial-side dates. When all three source types exist in the same searchable index, the chronological picture becomes three-dimensional.
Constructing the Episode Timeline
The practical workflow for building episode timelines from research follows a consistent pattern.
Phase one: Subject search. Search your TabVault archive for the episode's primary subject -- a person's name, a company name, an event identifier. Review every result, noting the dates visible on each indexed page. Court filing dates, article publication dates, document creation dates, email timestamps.
Phase two: Date extraction. From the search results, extract every date into a simple chronological list. Do not filter yet. Include the date, the source type (court record, news article, FOIA document), and enough context to identify the specific event. A list might begin: "2017-03-14, corporate filing, LLC registered in Delaware. 2017-06-22, news article, local paper reports on contract award. 2017-09-01, court docket, civil suit filed."
Phase three: Gap identification. The chronological list will reveal gaps -- periods where no dates appear. These gaps tell you where additional research is needed. If your subject registered an LLC in March and was sued in September, but you have no indexed pages covering June through August, that is a research gap, not an event gap. Search your archive more broadly, or plan new research sessions to fill the hole.
Phase four: Narrative sequencing. With the chronological list complete and gaps filled, you have the backbone for your episode. The dates dictate the narrative sequence. The timeline tells you which events to introduce first, where to create narrative tension through chronological juxtaposition, and where the story accelerates or stalls.
Advanced Tactics for Indexed Research Session Timelines
Cross-session date comparison. When the same date appears in multiple indexed sessions -- a court filing date from your docket search matches a news publication date from your archive search -- you have found a moment of convergence. These convergence points are often the most dramatic moments in an investigative narrative. Someone filed a lawsuit the same day a newspaper published an expose. That is not a coincidence; it is a story beat.
Multi-source verification. For every critical date in your timeline, search your archive for corroborating sources. If a court docket says a hearing occurred on October 15, search for news coverage of that hearing, FOIA documents referencing it, or meeting minutes from the same date. Indexed research session timelines built from multiple source types are more defensible than those relying on a single record. The GIJN's guide to deep internet research stresses that open-source investigators should cross-reference data from various sources to verify information and highlight inconsistencies -- and date verification across your indexed sessions is the most concrete application of that principle.
Season-spanning timelines. Investigations that run across multiple seasons need timelines that span years of research. The indexed sessions from season one remain searchable during season three's production, allowing you to build a continuous chronology without re-doing early research.
Timeline as quality control. Before publishing an episode, review the timeline for internal consistency. Do the dates in your script match the dates in your indexed sources? Search your archive for every date mentioned in the script and verify it against the original source page. Researchers maintaining searchable archives for case research use the same verification technique to ensure accuracy.
Establish a date-verification checkpoint before recording. Before finalizing any episode script, extract every date from the draft and search your TabVault archive for each one. Confirm that the indexed source page supports the date as written. This systematic verification catches transposition errors, conflated dates from different events, and dates that were approximate in one source but stated as definitive in the script. The checkpoint takes thirty minutes and prevents corrections that could cost the show's credibility.
Use the timeline to identify narrative pacing. Once you have a chronological list with all gaps filled, the timeline reveals where the story moves quickly -- clusters of events within days -- and where it slows to a crawl -- months with no indexed activity. These pacing variations translate directly into episode structure. Rapid event clusters suggest a single episode covering a pivotal week. Long gaps suggest a reflective segment or a jump forward with narration bridging the silence.
If your investigative podcast episodes require precise timelines and you are spending days reconciling scattered dates from closed browser sessions, the research is working against the narrative. TabVault keeps every date-bearing page you visited searchable and connected to its source, so the timeline builds as naturally as the research itself. Join the waitlist to turn months of browsing sessions into the chronological backbone your episodes need.