Best Practices for Organizing DNA Cluster Analysis Research
Four Colors, Forty Tabs Per Color, Zero Organization
Dana Leeds developed the Leeds method in 2018 to help genetic genealogists sort DNA matches into ancestral groups without needing family trees. As Dana Leeds explains on her site, the method uses shared matching to create colorful groups of matches, where each group is likely related through one part of the family. For unknown parentage cases, where the cousins are strangers and their true relationships are unknown, the method works particularly well.
The method itself is elegant. You take your AncestryDNA matches between 90 and 400 cM, check which ones share DNA with each other, and assign colors. In an ideal case, you get four clusters corresponding to four grandparent lines. The whole sorting process takes an hour or two.
The problem begins the moment you start researching the clusters. Each cluster might contain fifteen to thirty matches. Each match has a profile page, a shared DNA detail page, potentially a linked family tree, and associated historical records. If you are thorough, you will open three to five tabs per match. Multiply that across four clusters and you are looking at hundreds of tabs over the course of a few weeks. The color-coded clarity of the Leeds method dissolves into browser chaos the moment you start doing the actual genealogy.
Researchers who have experienced how browser chaos derails parentage investigations know this pattern well. The initial organization scheme -- however good -- collapses under the weight of unmanaged browser sessions.
Organizing Cluster Research in Indexed Sessions
The solution is to treat each DNA cluster as a separate research project with its own indexed sessions. TabVault turns chaotic browser sessions into a searchable private database, and when you structure those sessions by cluster, the database itself becomes organized by ancestral line.
One cluster per session. When you sit down to research your blue cluster (grandparent line one), you open only the match profiles, family trees, and historical records relevant to that cluster. Everything you visit during that session gets indexed together. The next day, you work your green cluster in a separate session. Each session becomes a self-contained, searchable block of research for one ancestral line.
Search within a cluster. When you need to recall which blue-cluster matches had trees that included anyone from Cuyahoga County, you search your indexed sessions for "Cuyahoga" within your blue-cluster research. The matches surface without you needing to reopen AncestryDNA and manually check each profile. This is AncestryDNA cluster management through searchable history rather than through spreadsheets.
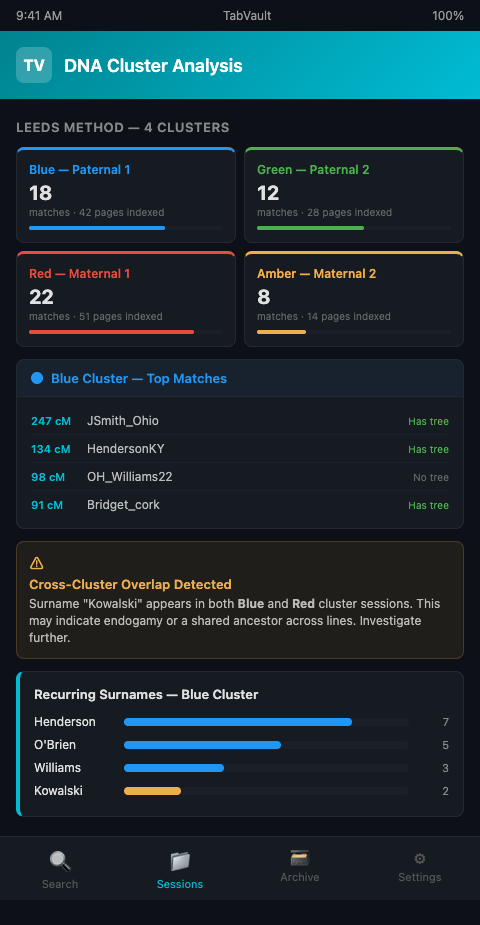
Cross-cluster comparison. The real analytical power emerges when a name or location appears in two different cluster sessions. If "Kowalski" appears in both your blue-cluster and red-cluster indexed sessions, that could indicate a connection between two grandparent lines -- or it could indicate endogamy. Either way, the cross-cluster hit is a finding that requires investigation. Family Locket documents that endogamy creates situations where matches appear in multiple clusters, making systematic tracking of these overlaps critical.
The Leeds Method Meets Full-Text Search
The Leeds method cluster research workflow has a specific sequence: sort matches into clusters, research each cluster to identify common ancestors, and then use those ancestors to build a family tree that connects back to the person being researched. Full-text search of indexed sessions accelerates every phase after the initial sort.
Identifying common ancestors within a cluster. As Your DNA Guide explains, the goal of the Leeds method is to quickly identify groups of people in your match list who likely share a common ancestor with each other. As you research each match in a cluster, you visit their family trees and associated records. Surnames and locations recur. With indexed sessions, you do not need to remember which match's tree contained "Bridget O'Brien born 1878 in County Cork." You search for it and find every page in your cluster research that mentions it. The shared DNA segment clustering that the Leeds method establishes becomes reinforced by shared documentary evidence surfaced through search.
Building speculative trees from cluster evidence. Once you identify a likely common ancestor for a cluster, you start building a descendancy tree. This means visiting census records, vital records, and other sources for each generation between the common ancestor and the living DNA matches. Each of these record pages gets indexed. When you need to verify a specific detail -- "Did the 1920 census show John O'Brien in Pittsburgh or Philadelphia?" -- you search your archive instead of re-navigating the original database.
Documenting dead ends. Not every match in a cluster will be resolvable. Some matches have no trees, no shared matches beyond the cluster, and no identifying information. Indexing the pages you visited while trying to research these matches documents the dead end. When a new match appears in the same cluster months later and provides the missing connection, you can search your archive to see exactly where you got stuck before. Researchers working on pattern detection across DNA match clusters over months depend on this kind of longitudinal research record.
Advanced Tactics for Genetic Genealogy Cluster Tracking
Handle endogamy-affected clusters with extra session discipline. Legacy Tree Genealogists explains that in endogamous populations, the amount of shared DNA does not accurately reflect genealogical relationships, and sorting matches into distinct clusters becomes difficult. When endogamy collapses your four clusters into two or three, maintain separate sessions for each theoretical line even if the clusters overlap. Your indexed sessions will document the overlap pattern, which is itself evidence of endogamy.
Track cM values alongside cluster assignments. When you research a match, index both their profile page (which shows shared cM) and their cluster assignment. Over time, this creates a dataset that shows the cM distribution within each cluster. Clusters with consistently higher cM values may represent closer shared ancestors. Researchers who also track centimorgan thresholds across multiple platforms can cross-reference platform-specific cM values with cluster assignments.
Use clusters to prioritize research. Not all clusters are equally productive. A cluster where several matches have detailed family trees will yield results faster than a cluster where no matches have trees. Review your indexed sessions to assess which clusters have the most researchable matches, and focus your time accordingly. Researchers working with indexed period hardware catalog tracking for salvage dealers use a similar prioritization approach based on which sources have the richest indexed content.
Revisit cluster assignments quarterly. AncestryDNA updates its matching algorithm periodically, and new testers appear in your match list continuously. Run the Leeds method again every few months and compare the new clusters against your previous indexed sessions. Matches that move between clusters or new matches that slot into existing clusters both represent new research opportunities.
Document sub-clusters within each grandparent line. A single Leeds cluster corresponding to one grandparent line often contains sub-groups that represent different branches of that grandparent's family. Matches who share DNA with each other at higher rates likely descend from the same great-grandparent pair within that line. By tagging your indexed sessions with both the cluster color and any emerging sub-group pattern, you create a hierarchical research structure that mirrors the actual family tree. When a new match appears in a cluster and shares DNA with only a subset of existing matches, your archive immediately shows which sub-group they belong to and which branch of the tree deserves further investigation.
If your Leeds method clusters are drowning in unorganized tabs, TabVault keeps each ancestral line's research separate, searchable, and growing. Join the waitlist to bring permanent structure to your DNA cluster analysis.