Privacy-First Indexing: Why Local Storage Protects Genetic Data
The Privacy Stakes of Genetic Research Data
The European Union's General Data Protection Regulation classifies genetic data as a special category of personal data requiring enhanced protections under Article 9. This classification reflects a biological reality: genetic data is inherently identifiable. Research published by the Global Alliance for Genomics and Health confirms that genomic data cannot be fully anonymized because re-identification strategies can determine individuals' names from DNA and minimal metadata. Unlike a password or credit card number, genetic data cannot be changed if compromised.
For genetic genealogists, this is not an abstract regulatory concern. Every research session involves viewing DNA match profiles that display shared centimorgan values, predicted relationships, and linked family trees. Many of the individuals in those match lists did not consent to being investigated. They submitted DNA for personal curiosity or health screening and appear in a forensic genealogist's research as a side effect of database participation. The privacy obligation extends beyond the researcher's own client to every person whose data appears in the investigation.
The scope of this exposure is substantial. A single unknown parentage case may involve examining 200 or more DNA match profiles, each belonging to a real person with privacy expectations. The researcher views their predicted relationships, their family tree connections, and sometimes their ethnic composition estimates. She may also view their shared matches, creating a web of relationship data that extends far beyond the individuals she is directly investigating. All of this data passes through her browser during normal research activity.
Cloud-based research tools create a specific risk in this context. When a browser extension or research platform uploads session data to a remote server, the content of DNA match profiles, the relationships between individuals, and the researcher's analytical notes all leave the researcher's machine. Even with encryption in transit and at rest, the data now exists on infrastructure controlled by a third party. That third party's security practices, employee access controls, and vulnerability to subpoena or breach become part of the researcher's privacy calculus.
The risk is not theoretical. Data breaches at consumer genetic testing companies have exposed millions of users' information. In 2023, 23andMe disclosed a breach that affected approximately 6.9 million users' profile information, including ancestry reports and self-reported location data. When a researcher's session data, which contains detailed notes about specific matches and their family relationships, sits on a cloud server, it becomes one more dataset that a breach could expose. The individuals whose match profiles were examined during the research never consented to having their genetic relationship data stored on a third-party server. The researcher bears the ethical responsibility for that exposure.
The DOJ's interim policy on investigative genetic genealogy requires that all data about third parties be destroyed after a case concludes, recognizing the sensitivity of genetic information obtained during investigations. This destruction requirement only works if the researcher knows where all copies of the data reside. Cloud storage complicates that accounting.
Local-First Architecture as a Privacy Foundation
TabVault takes a local-first approach to indexing, keeping all session data on the researcher's own machine rather than transmitting it to external servers. This design turns chaotic browser sessions into a searchable private database that remains genuinely private. The index lives on local storage, the search runs locally, and the full-text content of visited pages never leaves the researcher's device.
For genetic data privacy local storage, this architecture provides three concrete benefits. First, the researcher maintains sole custody of the data. There is no cloud provider whose security policies need to be evaluated, no terms of service that might grant the provider access to stored content, and no remote server that could be breached. Second, the data is subject only to the researcher's own data retention policies. When a case concludes and the researcher needs to destroy session data to comply with the DOJ's destruction requirements or a client's privacy preferences, deletion is local and verifiable. Third, the architecture eliminates the jurisdictional complexity that arises when data crosses borders. A European researcher's genetic data does not land on a U.S. server, and vice versa.
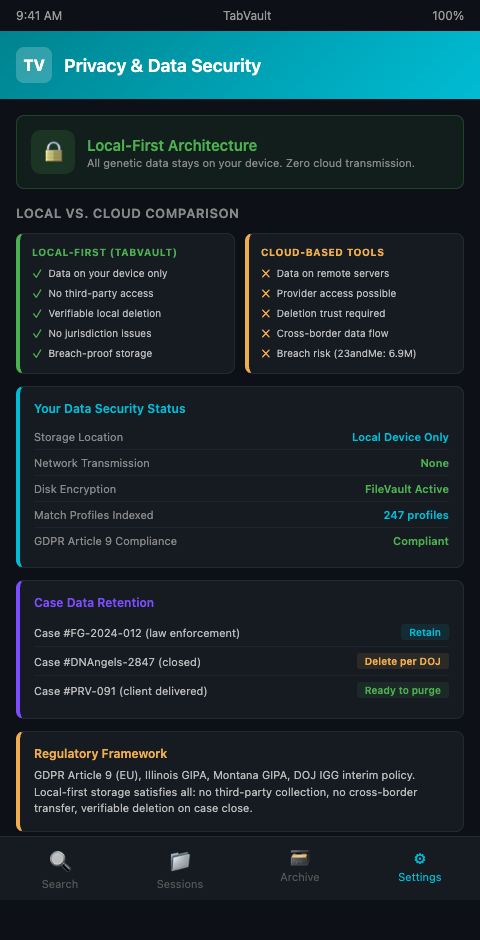
This approach to DNA research data protection aligns with the broader principle that the most sensitive data should have the smallest possible attack surface. Every additional system that touches the data, every network transmission, every remote storage location, adds a potential point of failure. Local-first genetic genealogy tools minimize that surface by keeping data handling within a single device.
The privacy architecture also supports the evidentiary requirements discussed in forensic genealogy evidence standards. When a forensic genealogist must demonstrate chain of custody for her research data, showing that the data never left her local machine is a stronger position than explaining the security practices of a cloud provider. The same principle drives source protection in investigative podcast production: when confidential source material is at stake, local storage is not a preference but a requirement.
Privacy Considerations Beyond Storage Location
The first advanced consideration is data minimization. Even with local storage, researchers should index only what they need. A private genealogy indexing security model should allow the researcher to exclude certain domains or session types from indexing. Medical information pages, for example, might appear during research into a match's family history but should not be retained in the archive if they are not relevant to the genealogical question.
The second consideration is device security. Local storage protects against cloud-based threats but shifts the security burden to the researcher's own device. Full-disk encryption, strong device passwords, and physical security for the machine become part of the DNA research data protection strategy. Researchers handling law enforcement cases should follow the same device security protocols they would apply to any other sensitive case material.
The third consideration involves collaborative research. When multiple researchers work on the same case, as discussed in cold case resolution workflows, data sharing must be deliberate rather than automatic. A local-first architecture means that sharing requires an explicit export and transfer action rather than happening as a background sync. This friction is a feature, not a bug. It ensures that sensitive genetic data only moves between researchers when a conscious decision is made to share it.
Research from Oxford Academic argues that the sensitivity of genetic data varies by context: aggregate population data carries different risks than individual match profiles. Researchers should calibrate their privacy practices to the sensitivity of what they are handling. A session spent browsing general population genetics articles does not carry the same risk as a session spent examining the DNA match profile of a living person who is a suspect in a criminal investigation.
A fourth consideration involves data retention timelines. Different cases have different retention requirements. A law enforcement case may require preserving all research data until the case is adjudicated, which could take years. A private client case may require deletion once the final report is delivered. Local-first storage gives the researcher granular control over retention: specific case archives can be preserved or deleted independently, on whatever timeline the case requires. Cloud storage complicates this control because the researcher must trust the provider to honor deletion requests completely.
Finally, local-first tools must still be auditable. Sensitive DNA data storage safety requires not just preventing unauthorized access but also demonstrating that access controls are in place. Researchers working forensic cases should document their local security measures as part of their case file, alongside the research itself. The documentation should specify what encryption is used, where the archive is stored, who has access to the device, and what deletion procedures will be followed when the case concludes. This documentation transforms a technical architecture choice into a demonstrable privacy commitment.
A fifth consideration is the emerging regulatory landscape. Laws governing genetic data are becoming more restrictive, not less. Several U.S. states have enacted or proposed genetic privacy legislation that goes beyond general data protection requirements. Illinois's Genetic Information Privacy Act, Montana's Genetic Information Privacy Act, and similar measures in other states create specific obligations around the collection, storage, and sharing of genetic data. Researchers who store session data containing genetic information on cloud servers may find themselves subject to compliance requirements that local-first storage avoids entirely, because data that never leaves the researcher's device is not "collected" or "stored" by a third party under most regulatory frameworks.
The intersection of DNA research data protection and professional ethics creates a clear directive: choose the storage architecture that minimizes exposure of the sensitive data you handle. Local-first is not just a technical preference. For genetic genealogists handling the most sensitive personal data in existence, it is the only architecture that fully aligns with the ethical obligation to protect the privacy of everyone whose data touches your research.
Keep Genetic Data Under Your Control
Private genealogy indexing security starts with a simple principle: sensitive data should not leave your machine unless you explicitly choose to share it. TabVault's local-first architecture keeps your research index on your device, under your control, with no cloud dependency. Join the waitlist to protect the genetic data your research depends on.
Every DNA match profile you examine during research contains genetic relationship data about real people who never consented to being investigated. That data deserves storage architecture that matches its sensitivity. TabVault keeps your entire research index on your local drive, encrypted and under your sole control, with zero data transmitted to any external server. When a case concludes and you need to verify that all session data has been destroyed, the deletion is local and auditable. Researchers handling law enforcement cases or sensitive adoption searches find that this local-first model is the only architecture that fully satisfies both DOJ destruction requirements and the ethical obligation to protect third-party genetic information.