Coordinating Tab Search Across Collaborative Investigation Teams
The Duplication Problem Nobody Tracks
The International Consortium of Investigative Journalists coordinated over 370 reporters in nearly 80 countries during the Panama Papers investigation, relying on custom-built platforms to index and search 2.6 terabytes of leaked documents (ICIJ). Most investigative podcast teams do not have ICIJ's engineering budget, but they face an identical structural challenge: multiple researchers browsing overlapping territory with no way to know what their teammates have already found.
A three-person team investigating a local corruption story might collectively open 400 tabs across county property records, court filings, corporate registrations, and news archives over a two-week sprint. Without a shared search layer, Producer A pulls the same deed transfer that Producer B found three days earlier. Producer C searches for a name that appears in a document Producer A bookmarked but never mentioned in the shared Google Doc. The Reuters Institute's research on collaborative investigative journalism found that coordination failures — not lack of skill — are the primary bottleneck in team-based investigations (Reuters Institute).
The Global Investigative Journalism Network describes the role of the "investigative coordinator" as someone who must maintain a thorough understanding of the investigation's material while managing communication across team members (GIJN). That understanding breaks down when the material lives in individual browser sessions that nobody else can search. The coordinator cannot maintain awareness of what they cannot access, and browser-based research is, by default, invisible to everyone except the researcher who conducted it.
Building a Shared Search Layer From Individual Sessions
The fix is not asking everyone to use the same browser or the same bookmarking system. The fix is giving each team member's browsing sessions a common searchable index. This is where turning chaotic browser sessions into a searchable private database becomes a team-level capability rather than an individual one.
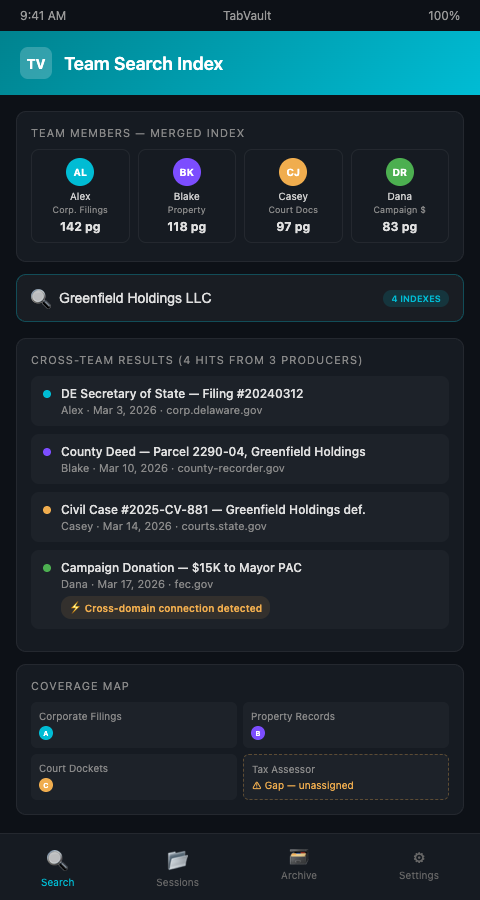
TabVault indexes the full text of every page a researcher visits during a session. When each producer on a collaborative investigation team runs TabVault locally, they build individual archives of their browsing research. The coordination step is merging those indexes — or querying across them — so the team can search all collected material from a single interface.
Consider a four-person team investigating a state-level procurement fraud story. Producer A focuses on corporate filings with the Secretary of State. Producer B pulls county property records and tax assessor data. Producer C monitors court dockets and civil litigation. Producer D tracks campaign finance disclosures. Each producer's TabVault instance indexes every page they visit. When the team syncs their indexes at the end of each day, a search for a company name or individual returns results from all four research tracks simultaneously.
This eliminates the duplication problem directly. If Producer B searches for "Greenfield Holdings LLC" and sees that Producer A already indexed a Secretary of State filing for that entity two days ago, there is no need to pull the same record. The search results show the timestamp, the source URL, and the indexed text — enough context to decide whether to dig deeper or move on.
The efficiency gains are concrete and measurable. A team that runs deduplication checks against the shared index before each research session avoids spending hours on records another producer already found. Over a six-month investigation, the cumulative time savings translate into additional research capacity — hours that can be redirected from redundant record-pulling to original source development, interview preparation, or deeper analysis of the connections the shared index reveals.
The architecture matters for source safety. Each producer's local index stays on their own machine. The shared search layer can operate through exported index snapshots rather than live cloud syncing, which means sensitive research data never passes through a third-party server. Veterinary practices coordinating research across multiple clinic locations use a similar multi-site tab search architecture to share indexed reference material without centralizing sensitive data.
TabVault's search also surfaces connections that no single researcher would notice. When Producer D's campaign finance pages contain the same individual name that appears in Producer B's property records, the cross-index search flags the overlap. These are the lateral connections that break investigations open — and they only become visible when the team's research is searchable as a unified corpus.
The same approach scales to multi-team environments where separate teams maintain independent indexes but can query across them for specific investigations. Teams working on different episodes or seasons can maintain isolated research silos until a cross-show connection warrants merging results.
The shared search layer also changes how team meetings work. Instead of each producer verbally summarizing their week's research — a process that loses detail and consumes editorial time — the team can query the merged index during the meeting. A producer mentions a name; the team searches the index and sees every page across all four research tracks that contains that name, sorted by date. The conversation shifts from "what did you find?" to "what does this connection mean?" — a qualitatively different editorial discussion.
Coordinating research across teams also means coordinating research timelines. When the merged index shows that Producer A indexed a specific corporate filing on March 3 and Producer C indexed a related court docket on March 10, the team can reconstruct the chronological development of the evidentiary trail across multiple researchers. This timeline view is especially valuable during pre-publication legal review, when the team needs to demonstrate the sequence of discovery not only the final set of findings.
Advanced Team Coordination Tactics
Assign search domains by researcher. Before a sprint, divide public record categories among team members so each person's index covers a distinct slice of the investigation. This reduces overlap and makes the merged index more comprehensive. When someone needs to cross into another producer's domain, they search the shared index first rather than starting from scratch.
Run deduplication checks weekly. Even with divided domains, researchers will pull the same documents from different angles. A weekly team deduplication pass through the merged index identifies redundant pages and flags them for consolidation. This keeps the shared archive clean and prevents conflicting versions of the same record from confusing the timeline. The deduplication process itself surfaces useful metadata — if two producers independently found the same record through different search paths, those paths may reveal alternative access routes worth documenting.
Use timestamped session labels. Each research session should carry a date and a brief topic label — "2026-03-15 / county deed transfers / Greenfield" — so the shared index is browsable by timeline as well as by keyword. When the team reviews its collective progress, these labels provide a chronological map of who researched what and when.
Establish a naming convention for entities. Research on collaborative investigative journalism has documented that digital tools like OCCRP's Aleph platform allow teams to cross-reference persons of interest and companies across shared datasets, making entity resolution a core capability for modern investigations (Tandfonline, 2018). Investigations involving corporate structures encounter the same entity under slightly different names — "Greenfield Holdings," "Greenfield Holdings LLC," "GFH Management." Agree on canonical names early and search for all variants periodically. TabVault's full-text search catches variant spellings that a tag-based system would miss, but a naming convention helps the team communicate clearly about which entity they mean.
Build the index before the editorial meeting. The merged search index is most valuable when the team can query it in real time during editorial discussions. When a producer raises a question — "Did anyone find a connection between the mayor's chief of staff and the property on Elm Street?" — the answer should be one search away, not a round of "let me check my bookmarks."
Create a cross-team search protocol for new leads. When a new person of interest or entity enters the investigation, the first step should always be searching the shared index. This five-second check prevents days of redundant work and immediately contextualizes the new lead within the team's existing research. Document the search and its results in the team's working notes so the lead's provenance is clear.
Maintain a shared investigation search database for cross-show archives if your network runs multiple shows. The team coordination model within a single show extends naturally to cross-show coordination within a network. The merged index principle is the same — the only difference is the scope of the contributing archives.
Track coverage gaps across the team. The shared index reveals what the team has found and what the team has not searched. If the merged index contains property records from three counties but none from the fourth county in the investigation's geographic scope, that gap is visible immediately. Coverage gap analysis turns the shared index into a research planning tool — the team can allocate the next sprint's effort based on where the index is thinnest.
Stop Coordinating Through Chat Threads
Slack messages and shared docs are communication tools, not research infrastructure. A collaborative investigation team tab search layer lets every producer find what the team already knows without asking. TabVault gives investigative podcast teams a private, searchable archive of their collective browsing research — team-based investigation research that scales with the team rather than fragmenting across individual browsers. If your team is losing time to duplicated effort and missed connections, join the waitlist and build the shared index your investigation needs.
A four-person team investigating state-level procurement fraud assigned each producer a distinct research domain: corporate filings, property records, court dockets, and campaign finance. When their merged TabVault index surfaced the same registered agent across all four domains, the cross-thread connection broke the investigation open -- a link no single producer would have found alone. Within three months, the team's shared index held 1,100 pages across 15 government databases, and their daily pre-session deduplication checks eliminated an average of six hours per week in redundant record-pulling. Join the waitlist and build the shared search layer your collaborative investigation needs.