The Investigative Podcaster's Guide to Organized Digital Research
When Pre-Production Research Lives in Five Places at Once
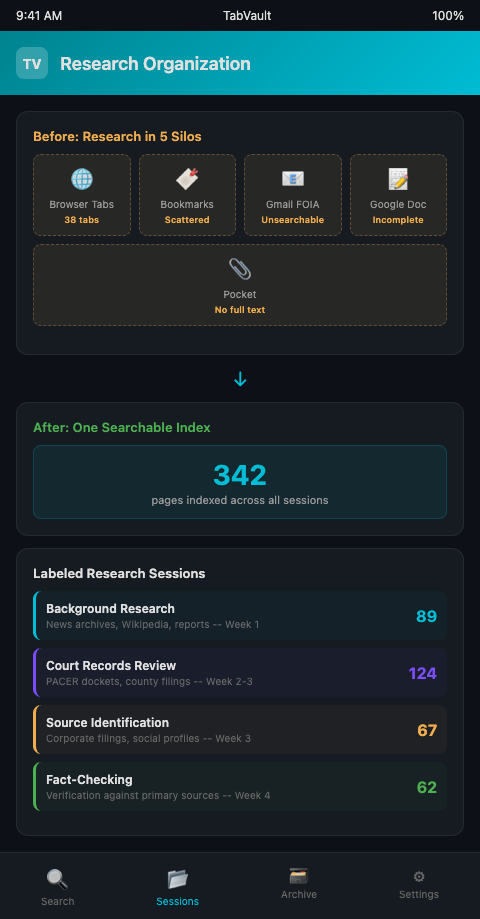
A two-person podcast team producing an investigative series on police misconduct described their research state midway through pre-production: court filings bookmarked in Chrome, FOIA correspondence in Gmail, source contact notes in a Google Doc, news clippings saved to Pocket, and background research spread across 38 open browser tabs that neither producer had organized or labelled. When the lead producer needed to verify a date mentioned in a court filing against a news article she had read the previous week, she spent 40 minutes hunting across all five systems before finding it in an open tab she had forgotten about.
This fragmentation is the default state of investigative podcast research organization. The Global Investigative Journalism Network documents that collaborative investigations require tools for at least three purposes — communicating, sharing documents, and managing the project — and that most teams underinvest in the document-sharing and search layer. For podcast teams, the problem is compounded by the volume of web-based research that never makes it into any formal system. Browser tabs are not a research management tool, but they are where most of the actual research lives.
Pre-production research planning for investigative podcasts follows a predictable arc documented by journalism programs at institutions like Georgetown University: desk-based investigation using public records, academic papers, and news archives, followed by source identification and field research. The desk-based phase generates the most browser tabs and the most organizational chaos, because it involves visiting dozens or hundreds of web pages across multiple research sessions without a clear stopping point.
The Society of Professional Journalists Code of Ethics requires verification against original sources. When your research is scattered across five systems, verification becomes a scavenger hunt. When it is unified in one searchable index, verification becomes a search query.
Building a Single Research Layer From Every Session
The organizing principle is simple: every web page you visit during research should flow into one searchable archive automatically. No manual copying. No separate bookmark categories. No switching between tools. One index, built as you browse, searchable by full text.
TabVault implements this for organized digital research by indexing the full rendered text of every page you visit. Court filings, news articles, FOIA portal pages, academic papers, government databases — all of it enters the same local index. The result is turning chaotic browser sessions into a searchable private database that grows with every research session and persists indefinitely.
For podcast research workflow management, this changes how pre-production operates. Instead of ending a research session by trying to organize what you found — bookmarking key pages, copying URLs into a spreadsheet, writing notes about what each page contained — you simply close the browser. The index already captured everything. When you need to find something later, you search for it by content, not by trying to remember where you saved it.
Research session management becomes a matter of labeling and filtering rather than manual compilation. Start each session with a label — "background research," "court records review," "source identification" — and every page indexed during that session carries the label. Later, search within a specific session type to narrow results, or search across all sessions to find every mention of a name regardless of when you encountered it.
From Research Sessions to Episode Building Blocks
The practical effect on pre-production research planning is that the research phase and the organization phase merge into one. There is no separate step where you catalogue what you found. The catalogue builds itself. This frees producers to focus on the substance of research — reading documents, identifying patterns, developing leads — rather than on the mechanics of filing and retrieval.
TabVault also creates a bridge between the desk-based and field-based phases of pre-production. When you go into a source interview, search your index for everything you have read about the person or topic. Review the relevant pages in minutes instead of hours. Prepare better questions because you have re-read the context, not skimmed your notes.
The archive also functions as a persistent knowledge base across episodes and seasons. A podcast that produces 20 episodes over two years accumulates a research archive spanning thousands of indexed pages. When a new season explores a topic tangentially related to a previous episode, the producer does not start from zero. She searches the existing archive for relevant terms and discovers research from 18 months ago that provides context, background, or leads for the new project. This compounding effect means the archive becomes more valuable with every session, not less.
For teams with multiple producers, the organized digital research approach creates a shared reference layer. When one producer indexes a critical court document and another needs to reference it during scripting, the indexed text is searchable by anyone with access to the archive. This eliminates the constant back-and-forth of "Can you send me the link to that thing you found?" that plagues teams relying on individual browser tabs and private bookmarks.
The same organizational challenge appears in other research-intensive professions. Veterinary toxicology responders face a parallel problem with emergency research scattered beyond bookmarks, where critical reference material gets lost across browser sessions during time-sensitive work. The indexed-archive approach applies across any discipline where web research accumulates faster than manual organization can track.
As your archive grows, the value extends into pre-production workflow optimization for later episodes. Research indexed during one investigation becomes relevant to a future project. A name that appeared in background research for an unrelated story might surface as a key figure in a new investigation. With a persistent, searchable archive, those connections become visible through a simple search rather than relying on producer memory.
Research session management also benefits from the predictability that an indexed archive provides. When a producer knows that everything browsed during a session will be captured and searchable, the anxiety of losing work disappears. The Carnegie Mellon tab behavior study identified that users keep tabs open out of fear that "as soon as something went out of sight, it was gone" (Carnegie Mellon University, 2021). An automatic index eliminates that fear and allows producers to close tabs freely, maintaining a cleaner workspace without sacrificing access to the underlying research.
Setting up portal indexing from day one ensures that no research session goes unindexed. The earlier you start, the more comprehensive your archive becomes, and the more value every future search delivers.
The difference between organized digital research and the default state of fragmented tabs, bookmarks, and notes is the difference between a team that can verify a claim in 30 seconds and a team that spends an afternoon hunting through five different systems. For podcast research workflow efficiency, that time savings translates directly into more thorough investigations, faster production cycles, and stronger editorial confidence in the facts behind every episode.
Advanced Tactics for Research Workflow Optimization
Conduct weekly archive reviews. Spend 15 minutes at the end of each week searching your index for the key names and terms in your current investigation. New indexed pages from the week's research may reveal connections to older material that you did not notice during the browsing session itself.
Use the archive for editorial meetings. Veterinary toxicology responders apply the same principle to emergency research that goes beyond bookmarks -- structured retrieval replaces memory-dependent workflows. Before an editorial meeting, search your index for the topics on the agenda. Pull up the most relevant indexed pages and share specific details with your team. This transforms editorial discussions from memory-based conversations into evidence-based planning sessions.
Build episode outlines from search results. When outlining a new episode, search your index for each major topic or scene. The search results become a curated bibliography of every source page relevant to that segment. Arrange the results in narrative order and you have a research-backed outline ready for scripting.
Index reference materials alongside investigation-specific research. Style guides, legal reference pages, and journalism ethics resources are pages you consult repeatedly. Indexing them puts their content into the same searchable layer as your investigation-specific research. When you need to check whether a reporting technique complies with SPJ guidelines, search rather than browse.
Separate personal browsing from research sessions. Use a dedicated browser profile or window for investigation research. This keeps your personal browsing — shopping, social media, entertainment — out of your research index, reducing noise in search results and keeping your archive focused on material that matters.
Create a post-publication review routine. After an episode airs, search your archive for the key claims in the episode and verify that the source material is complete and accessible. This review catches any gaps in your evidence base while the material is still fresh and helps prepare for potential challenges from subjects or legal representatives.
Use the archive for grant and pitch documentation. When applying for journalism grants or pitching a new series, search your archive to demonstrate the depth and breadth of research already completed. A searchable archive provides concrete evidence of the investigation's scope, which strengthens grant applications and network pitches alike.
Your Research Deserves a System That Matches Its Depth
Investigative podcast pre-production generates hundreds of pages of web-based research. Scattering that research across tabs, bookmarks, email, and notes is a structural weakness that slows verification, obscures connections, and risks data loss. TabVault unifies everything into one searchable, private, local archive. Join the waitlist and give your research the organizational backbone it demands.
A police misconduct investigation scattered across Chrome bookmarks, Gmail threads, Google Docs, Pocket saves, and 38 open tabs is an investigation waiting to lose critical evidence. TabVault collapses those five silos into one searchable layer -- every page indexed automatically as you browse. When a two-person team needs to verify a date from a court filing against a news article, the answer arrives in a five-second search instead of a 40-minute hunt. After eight weeks of pre-production, your unified archive holds every source you consulted, organized by content rather than by which tool you happened to save it in. Join the waitlist and give your research a system that matches its depth.