Where Browser-Based Clinical Decision Support Is Heading in Vet Tox
The 2010 Workflow in a 2025 Emergency
Dr. Torres treats a golden retriever presenting with acute vomiting and ataxia after ingesting an unknown substance from a neighbor's garage. She opens Chrome, types "dog unknown toxin vomiting ataxia garage chemicals" into Google, and begins scanning results. She clicks through an ASPCA page, a VIN thread, a Merck Veterinary Manual entry, and a PubMed abstract. She cross-references dosing information between two tabs. She copies a phone number for the ASPCA Animal Poison Control Center. The entire process takes fourteen minutes.
This workflow has not changed meaningfully in fifteen years. The underlying technology has transformed — search algorithms are better, reference sites are more comprehensive, mobile access is universal — but the cognitive process remains the same: a clinician manually querying the open web, filtering results by relevance, and synthesizing information across multiple pages under time pressure. The Journal of Veterinary Emergency and Critical Care regularly publishes studies on treatment protocol adherence in emergency settings, and time-to-treatment remains one of the strongest predictors of outcome in acute toxicosis cases.
The inefficiency is structural. The open web is not organized around veterinary clinical decisions. A Google search for a toxin returns consumer safety pages, human medical references, veterinary resources, and marketing content in an undifferentiated list. The clinician must perform the filtering that the technology should be doing. This is where browser-based clinical decision support for veterinary toxicology has the most room to advance.
The National Library of Medicine has been expanding veterinary-specific content in its databases, and the ASPCA maintains the most comprehensive animal toxin database in North America with records on over 1,000 toxic substances. But these resources sit behind general-purpose search interfaces that do not know the clinician is treating a 30-kilogram golden retriever with a two-hour exposure window to a suspected organophosphate.
The Indexed Archive as Decision Support Foundation
The next-generation veterinary emergency tools will not replace these resources — they will sit on top of them. And the critical foundation is the indexed archive that captures, organizes, and makes searchable every clinical research session a practice generates.
Consider what an indexed archive provides that a live web search does not. A practice with twelve months of indexed sessions has a corpus of toxicology pages that reflects its actual caseload, its clinicians' preferred resources, and the specific protocols that have worked in its patient population. When Dr. Torres searches her TabVault archive for "vomiting ataxia organophosphate," she gets results weighted toward the resources her practice actually uses — not the generic ranking of a search engine optimizing for click-through rates.
This is the embryonic form of browser-based clinical decision support veterinary toxicology. The indexed archive is a curated, practice-specific knowledge base that turns chaotic browser sessions into a searchable private database. Today, it supports faster retrieval. Tomorrow, it supports predictive assistance.
The veterinary toxicology decision support future includes several developments that build directly on indexed archives:
Contextual search suggestions. When a clinician begins typing a search query, the system can suggest completions based on the practice's indexed history. If the archive contains frequent research on "chocolate theobromine canine," typing "chocolate" surfaces that complete query path immediately. This is not a web search autocomplete — it is a practice-specific recommendation based on actual clinical research patterns.
AI-assisted toxin identification from clinical signs. A clinician entering "tremors, hypersalivation, seizures, outdoor dog" into a search interface backed by an indexed archive and a toxicology knowledge graph could receive a ranked list of probable toxins — metaldehyde, organophosphate, strychnine — each linked to the practice's own indexed treatment protocols for that substance. The AI-assisted toxin identification layer does not generate novel medical advice; it cross-references clinical presentation against the archive's indexed content to surface the most relevant resources faster.
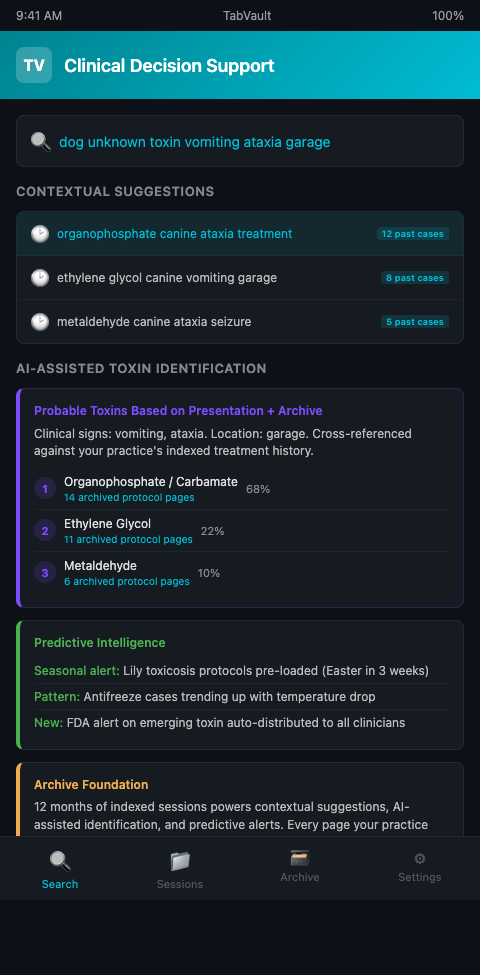
Predictive toxicology browser tools. Combining indexed research history with seasonal toxin pattern data creates predictive capability. If the archive shows that the practice has researched lily toxicosis twelve times every April for three consecutive years, the system can proactively surface lily treatment protocols in late March — before the first case arrives. Predictive toxicology browser tools transform historical data into anticipatory clinical support.
Cross-case learning. When a clinician researches a case with a rare presentation, the clinical knowledge captured from that session becomes available to every future clinician who encounters a similar presentation. The system learns not from a central training dataset but from the practice's own clinical experience, indexed session by indexed session.
TabVault's current capability — full-text indexing, local storage, timestamped search — is the infrastructure layer that makes all of these future capabilities possible. Without a comprehensive, practice-specific indexed archive, predictive and AI-assisted features have nothing substantive to work with. The archive is the dataset. Building it now means the practice is ready for the tools that emerge next.
The Trajectory for Emergency Practices
From retrieval to triage support. Current browser-based research supports treatment decisions after a diagnosis is formed. Next-generation tools will support the triage phase — helping clinicians narrow down the probable toxin while the patient is still being stabilized. An indexed archive containing hundreds of past toxicosis research sessions provides the reference corpus for this triage assistance.
From individual to collective intelligence. Today, each clinician searches their own or their practice's archive. Future tools will aggregate anonymized search patterns across practices — identifying emerging toxins, new product risks, and regional exposure trends. The future of browser-based investigative tools in other fields points toward the same trajectory: individual archives feeding into collective intelligence networks while preserving privacy.
From passive indexing to active alerting. The AVMA has noted that artificial intelligence is poised to transform veterinary care, with decision support tools already emerging that analyze diagnostic data and surface relevant clinical patterns. When a clinician indexes a page describing a newly identified toxin risk — a product recall, an FDA alert, a case report on an emerging toxic substance — next-generation veterinary emergency tools could push that information to every clinician at the practice, not just the one who happened to read it. The indexed archive becomes a distribution channel for clinical intelligence.
From text to multimodal indexing. Current full-text indexing captures rendered text from web pages. Future indexing will incorporate images (clinical photographs of toxicosis presentations), tabular data (dosing charts), and structured data (drug interaction matrices). The browser-based clinical decision support layer will grow richer as the types of content it can index expand.
From local archives to federated knowledge networks. The natural endpoint of practice-level indexed archives is a federated network where practices can opt into anonymized, aggregate-level sharing. A practice in Phoenix that indexed research on Sonoran Desert toad toxicosis could contribute anonymized protocol data to a network that practices in other toad-endemic regions can query. No patient data crosses practice boundaries — only the reference material and research patterns that clinicians found useful for specific toxin presentations. This federated model preserves the privacy guarantees of local-first indexing while unlocking collective intelligence that no single practice could generate alone. The foundation for this future is the comprehensive, timestamped archive that practices begin building today.
Build the Foundation Now
The clinical decision support tools of 2030 will depend on the archives built in 2025. Every toxicology page your practice indexes today contributes to the dataset that future AI-assisted, predictive, and contextual tools will draw from. TabVault provides the indexing infrastructure that makes this future possible. Join the waitlist to start building the foundation your practice's next decade of clinical decision support requires.
The clinical decision support tools of 2030 will run on the archives that practices build today. TabVault provides the indexing infrastructure — capturing every ASPCA consultation, every VIN specialist discussion, every PubMed treatment comparison your team reviews — and stores it locally as the foundation for contextual search suggestions, AI-assisted toxin identification, and predictive seasonal alerting that will emerge as the next generation of veterinary emergency tools matures. Practices that start building comprehensive indexed archives now will be the ones positioned to adopt those capabilities first, with years of practice-specific clinical data already in place.